Quando falamos em Deep Learning, é comum pensar em coisas futuristas: carros autônomos, reconhecimento facial, ou modelos que geram textos e imagens com realismo impressionante.
Mas tudo começou de forma muito mais simples — com uma tentativa de imitar o cérebro humano por meio de um único neurônio artificial.
Essa ideia, embora pareça ingênua hoje, foi o primeiro passo rumo às redes neurais profundas que moldam a inteligência artificial moderna.
O presente artigo tem como objetivo introduzir os fundamentos do Deep Learning, contextualizando-o dentro do campo do aprendizado de máquina e explicando sua base teórica inspirada no funcionamento do cérebro humano.
O que é Deep Learning?
O Aprendizado de Máquina (Machine Learning) é uma área da Inteligência Artificial que ensina computadores a reconhecer padrões e tomar decisões baseadas em dados.
Dentro do ML, há várias famílias de algoritmos, como:
Categoria |
Exemplos |
Características |
|---|---|---|
Supervisionado
|
Regressão Linear, Árvores, SVM, KNN
|
Aprende com dados rotulados (entrada -> saída)
|
Não Supervisionado
|
K-Means, PCA
|
Encontra padrões ocultos em dados sem rótulo
|
Por Reforço
|
Q-Learnig, Deep Q-Networks
|
O Deep Learning é uma subárea do aprendizado de máquina (ML — Machine Learning) que busca reproduzir, de forma computacional, aspectos do aprendizado humano utilizando redes neurais artificiais (ANNs – Artificial Neural Networks). Ele é a base de tecnologias modernas como reconhecimento de fala, tradução automática, visão computacional e sistemas de recomendação.
Diferente de modelos tradicionais de ML, que requerem engenharia manual de atributos (feature engineering), o Deep Learning é capaz de extrair representações hierárquicas de dados por meio de redes neurais profundas (GOODFELLOW; BENGIO; COURVILLE, 2016).
Em resumo:
- Machine Learning tenta aprender funções matemáticas que mapeiam entrada → saída.
- Deep Learning faz o mesmo, mas usando várias camadas de neurônios artificiais que aprendem representações hierárquicas dos dados.
Exemplo de Hierarquia de Aprendizado
Pense em uma rede neural que reconhece gatos em imagens:
Camada |
O que aprende |
|---|---|
1ª camada
|
Bordas, linhas, cores básicas
|
2ª camada
|
Formas simples (orelhas, olhos)
|
3ª camada
|
Combina formas em rostos ou corpos
|
Última camada
|
Reconhece o "gato" completo
|
Ou seja, cada camada aprende níveis de abstração mais altos dos dados anteriores — daí o nome Deep (profundo).
Analogia simples
Pense em como você aprende algo novo:
- Você vê vários exemplos.
- Seu cérebro identifica padrões (cores, sons, formas).
- Ele cria conexões entre neurônios e ajusta as “forças” dessas conexões.
- Com o tempo, você reconhece o padrão com facilidade.
As redes neurais artificiais fazem algo parecido — mas em forma matemática. Porém antes de mergulhar em arquiteturas complexas como Convolutional Neural Networks (CNNs) ou Transformers, é essencial compreender os blocos fundamentais que sustentam essas redes: os neurônios artificiais e seu processo de aprendizado.
Estrutura geral de um modelo de Deep Learning
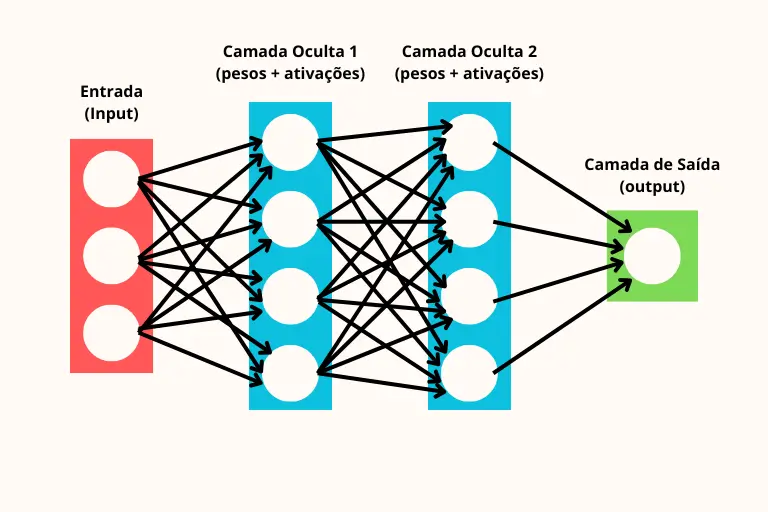
Cada camada tem neurônios artificiais, que:
- Recebem valores de entrada,
- Multiplicam por pesos (w),
- Somam um bias (b),
- Aplicam uma função de ativação (para decidir se “disparam” ou não um neurônio),
- Nas camadas ocultas aprendem representações internas dos dados.
Em forma matemática
Para um neurônio simples:
\(y = f(w_1x_1 + w_2x_2 + \dots + w_nx_n + b)\)
onde:
- \(x_i\) são as entradas (características),
- \(w_i\) são os pesos,
- \(b\) é o bias,
- \(f\) é a função de ativação (sigmoid, ReLU, etc.), ela define o comportamento “não linear” dos neurônios,
- \(y\) é a saída do neurônio.
Da biologia à computação: a inspiração do neurônio
O ponto de partida histórico das redes neurais artificiais está na tentativa de modelar o comportamento do cérebro humano. Um neurônio biológico é uma célula do cérebro composto por dendritos, que recebem sinais de outros neurônios; o corpo celular, que integra esses sinais; e o axônio, que transmite um impulso elétrico a outros neurônios caso o sinal combinado ultrapasse certo limiar (HAYKIN, 2009).
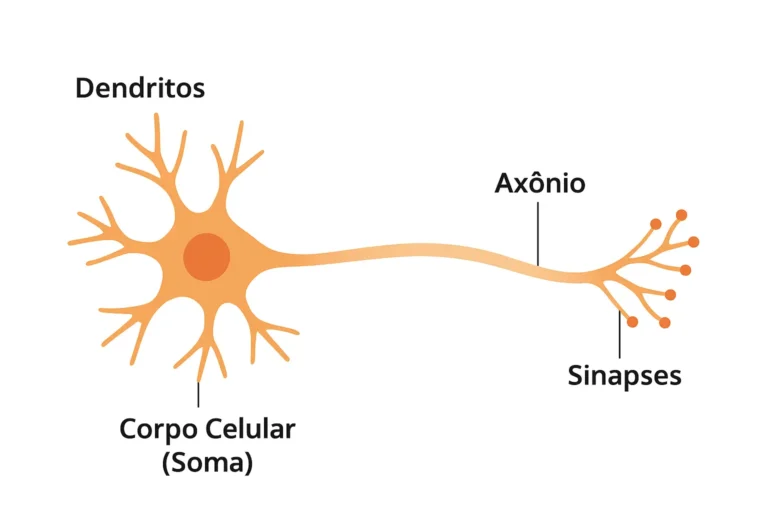
Função de cada parte:
Parte |
Função |
|---|---|
Dendritos
|
Recebem sinais elétricos de outros neurônios.
|
Soma (Corpo Celular)
|
Processa os sinais recebidos e decide se o neurônio “dispara” (ou não).
|
Axônio
|
Transmite o sinal elétrico para outros neurônios.
|
Sinapses
|
Pontos de conexão entre neurônios — onde ocorre a transmissão química do sinal.
|
Em resumo:
- O neurônio recebe sinais pelos dendritos.
- Ele soma esses sinais e, se o total for forte o bastante, dispara um impulso elétrico (potencial de ação).
- Esse sinal segue pelo axônio e é enviado para outros neurônios.
O neurônio artificial (o modelo matemático)
Inspirados nessa estrutura, Warren McCulloch e Walter Pitts (1943) propuseram o primeiro modelo matemático de um neurônio artificial. Seu objetivo era representar o processo de decisão binária do cérebro por meio de uma combinação linear de entradas, seguida de uma função de ativação que decide se o neurônio “dispara” (ativa) ou não.
Ele faz algo matematicamente equivalente:
- Recebe múltiplos sinais de entrada \((x₁, x₂, x₃…)\).
- Multiplica cada um por um “peso” \((w₁, w₂, w₃…)\).
- Soma tudo e adiciona um bias \((b)\).
- Aplica uma função de ativação que decide se o neurônio “dispara” ou não.
O papel da função de ativação (“ativar” ou “não ativar”)
A função de ativação é o que dá “vida” ao neurônio. Sem ela, a rede seria apenas uma sequência de multiplicações e somas — um modelo linear simples. Mas o mundo real não é linear, e as ativações permitem capturar relações complexas.
Função |
Equação |
Gráfico (conceito) |
Uso típico |
|---|---|---|---|
Degrau (Step)
|
\(f(x)=1 se x>0, senão 0\)
|
On/Off
|
Perceptron clássico
|
Sigmoid
|
\(f(x) = \frac{1}{1 + e^{-x}}\)
|
Curva em “S”
|
Saída entre 0 e 1
|
ReLU
|
\(f(x)=max(0,x)\)
|
Linear positiva
|
Camadas ocultas modernas
|
Tanh
|
\(f(x)=tanh(x)\)
|
Curva centrada em 0
|
Modelos antigos / RNNs
|
O neurônio artificial: Perceptron
Em 1958, o psicólogo e cientista Frank Rosenblatt apresentou o Perceptron, inspirado no funcionamento do cérebro humano, com a promessa de uma máquina que pudesse “aprender por si mesma”.
Ele foi implementado fisicamente em hardware (chamado Mark I Perceptron) e é considerado o primeiro modelo de rede neural treinável. Embora hoje seja simples, o Perceptron foi um marco histórico, pois trouxe a ideia de:
“Ajustar pesos automaticamente com base nos erros de predição.”
O processo de aprendizado do Perceptron ocorre ajustando os pesos com base no erro cometido:
\(w_i←w_i+η (y_{real}−y_{previsto})x_i\)
onde \(η\) é a taxa de aprendizado. Assim, o modelo gradualmente aprende a separar corretamente as classes no espaço de dados — desde que o problema seja linearmente separável (ROSENBLATT, 1958).
Estrutura do Perceptron
Visualmente, podemos imaginar o perceptron assim:
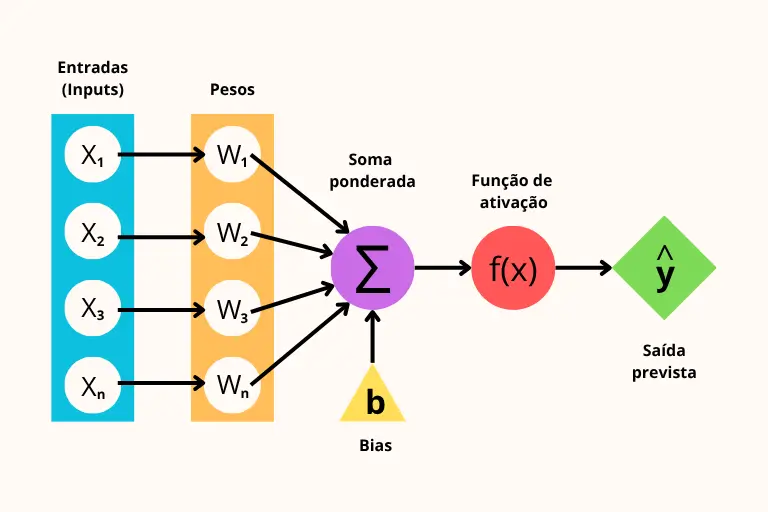
Matematicamente:
\(\hat{y} = f(w_1x_1 + w_2x_2 + \dots + w_nx_n + b)\)
onde:
- \(x_i\): entradas (características),
- \(w_i\): pesos,
- \(b\): bias,
- \(f\): função de ativação,
- \(\hat{y}\): saída prevista (predição do modelo).
Intuição: o que ele faz?
O perceptron é basicamente um classificador linear binário. Ele tenta encontrar uma linha (em 2D), ou um plano (em 3D), que separa dois grupos de pontos no espaço.
Exemplo: Queremos classificar se uma fruta é maçã (0) ou laranja (1) com base em peso e cor. O perceptron vai tentar encontrar uma fronteira de decisão linear que separe os exemplos.
Como o Perceptron aprende
O aprendizado acontece ajustando os pesos (w) e o bias (b) de forma a reduzir os erros de classificação. O processo segue um ciclo chamado regra de atualização do Perceptron:
1. Inicialização: Começamos com pesos e bias aleatórios (pequenos valores).
2. Predição: Para cada amostra, calculamos:
\(\hat{y} = f\left(\sum_{i=1}^{n} w_ix_i + b\right)\)
3. Comparação: Comparamos com o rótulo verdadeiro \(y\).
4. Atualização: Se o perceptron errou, ajustamos os pesos:
\( w_i \leftarrow w_i + \eta(y – \hat{y})x_i \)
e o bias:
\( b \leftarrow b + \eta(y – \hat{y}) \)
onde \(η\) (eta) é a taxa de aprendizado (learning rate).
Intuição do processo de aprendizado
Imagine o perceptron como alguém tentando desenhar uma linha separando pontos vermelhos e azuis num gráfico:
- Ele começa com uma linha aleatória.
- Vê um ponto azul classificado como vermelho → “opa, errei”.
- Move a linha um pouquinho para corrigir.
- Repete o processo até quase não errar mais.
Cada iteração é chamada de época (epoch), e o algoritmo percorre todos os dados de treino a cada época.
A função de ativação no Perceptron
Rosenblatt usou uma função de ativação em degrau (step function), que decide se o neurônio “dispara” ou não:
\(f(z) = \begin{cases}
1, & \text{se } z \geq 0 \\
0, & \text{se } z < 0
\end{cases}\)
Isso o torna um classificador binário (duas classes). Mas, como vimos antes, funções como sigmoid ou ReLU podem ser usadas em versões modernas para problemas mais complexos.
Exemplo conceitual
Entrada \(x_1\) |
Entrada \(x_2\) |
Saída \(y\) |
|---|---|---|
0
|
0
|
0
|
0
|
1
|
0
|
1
|
0
|
0
|
1
|
1
|
1
|
Este é o AND lógico. O Perceptron pode aprender essa relação! Ele ajustará os pesos até conseguir que:
- \(x_1 = 1, x_2 = 1 ⇒ y = 1\)
- Todas as outras combinações deem 0.
Camadas, pesos, bias e função de custo
O Perceptron simples tem apenas:
- uma camada de entrada (os dados), e
- uma camada de saída (a decisão binária).
Uma única unidade de Perceptron pode resolver apenas problemas linearmente separáveis, como distinguir pontos em lados opostos de uma linha. Para lidar com problemas mais complexos, conectamos múltiplos neurônios em camadas. Essas camadas formam as redes neurais artificiais (ANNs), onde cada neurônio da camada seguinte recebe como entrada as saídas da camada anterior.
Cada camada transforma as informações da anterior, aprendendo representações cada vez mais complexas.
Tipos de camadas
Tipo de camada |
Função |
|---|---|
Camada de entrada
|
Recebe os dados brutos (ex: pixels de imagem, atributos numéricos)
|
Camadas ocultas
|
Fazem combinações e transformações dos dados — onde o aprendizado “profundo” acontece
|
Camada de saída
|
Gera o resultado final (ex: probabilidade de ser gato ou cachorro)
|
Cada camada tem vários neurônios, e cada neurônio tem seus próprios pesos e bias.
Representação matemática
Vamos representar uma rede neural de 2 camadas (1 camada oculta + 1 saída):
\(Entrada X = [x_1,x_2, … ,x_n]\)
1. Camada oculta:
\(z^{(1)} = W^{(1)}X + b^{(1)}\)
\(a^{(1)} = f(z^{(1)})\)
2. Camada oculta:
\(z^{(2)} = W^{(2)}a^{(1)} + z^{(2)}\)
\(\hat{y} = f(z^{(2)})\)
onde:
- \(W^{(i)}\): matriz de pesos da camada \(i\)
- \(b^{(i)}\): vetor de bias
- \(f(⋅)\): função de ativação (Sigmoid, ReLU, etc.)
- \(a^{(i)}\): saída (ativação) da camada
Cada camada transforma as ativações da camada anterior até chegar à saída final.
Cada linha (conexão) tem um peso associado. O modelo aprende quais conexões são importantes e quais devem ser enfraquecidas.
Intuição sobre pesos e bias
- Pesos (w): controlam a força da influência de cada entrada sobre o neurônio.
- Bias (b): desloca o ponto de ativação da função (permite ajustar o limiar de decisão).
Se compararmos com uma linha reta:
\(y = w_1x + b\)
O peso muda a inclinação, e o bias move a linha para cima ou para baixo. Nas redes neurais, o mesmo raciocínio vale, só que em várias dimensões.
O papel das funções de ativação nas camadas
Sem uma função de ativação, toda a rede seria apenas uma grande multiplicação linear — e isso não aprenderia padrões complexos.
A função de ativação:
- introduz não linearidade no modelo,
- permite aprender relações complexas, como curvas, interações, e padrões visuais.
As mais comuns:
Função |
Fórmula |
Onde é usada |
|---|---|---|
ReLU
|
\(f(x) = max(0,x)\)
|
Camadas ocultas (padrão atual)
|
Sigmoid
|
\(f(x) = 1/(1+e^({−x}))\)
|
Saídas binárias
|
Tanh
|
\(f(x) = tanh(x)\)
|
Camadas intermediárias mais antigas
|
Softmax
|
\(f(x_i) = \frac{e^{x_i}}{\sum_{j} e^{x_j}}\)
|
Saídas com múltiplas classes
|
O papel da função de custo (ou perda)
A função de custo (loss function) mede o quão errado o modelo está. Durante o treinamento, a rede tenta minimizar essa função ajustando seus pesos e bias.
Alguns exemplos:
Tipo de problema |
Função de custo típica |
Fórmula |
|---|---|---|
Regressão
|
Erro Quadrático Médio (MSE)
|
\(L = \frac{1}{n} \sum (y - \hat{y})^2\)
|
Classificação binária
|
Entropia cruzada binária
|
\(L = -\frac{1}{n}\sum [y\log(\hat{y}) + (1-y)\log(1-\hat{y})]\)
|
Multiclasse
|
Entropia cruzada categórica
|
\(L = -\sum_i y_i \log(\hat{y}_i)\)
|
A função de custo é o “termômetro” do aprendizado — ela diz à rede se está indo na direção certa ou não.
Ciclo geral de uma rede neural
- Entrada: o modelo recebe os dados.
- Propagação: calcula as ativações de cada camada (feedforward).
- Saída: gera uma predição \(\hat{y}\).
- Cálculo do erro: compara (\hat{y}\) com o valor real \(y\).
- Ajuste dos pesos: (feito com o algoritmo de backpropagation, que veremos no próximo tópico).
- Repetição: o processo é repetido por várias épocas até o erro ficar pequeno.
Pense numa rede neural como uma cadeia de tradutores:
- A 1ª camada “traduz” pixels em bordas,
- A 2ª transforma bordas em formas,
- A 3ª transforma formas em objetos,
- A última decide “é um gato” ou “não é um gato”.
Cada camada aprende a linguagem da anterior, até que o modelo entenda o mundo de forma hierárquica.
Aprendizado: gradiente descendente e retropropagação
Uma rede neural começa com pesos aleatórios — ou seja, ela “não sabe nada”.
Durante o treinamento, ela:
- Faz uma previsão (feedforward);
- Mede o erro entre o resultado previsto e o esperado;
- Ajusta os pesos para reduzir esse erro na próxima vez.
Esse processo se repete muitas vezes, e aos poucos a rede “aprende”.
O que é o gradiente descendente?
O gradiente descendente é o método usado para ajustar os pesos e minimizar o erro da rede.
Imagine que temos um gráfico onde:
- O eixo x representa os valores possíveis dos pesos;
- O eixo y representa o erro (função de custo).
O objetivo é encontrar o ponto mais baixo da curva — onde o erro é mínimo. Mas não sabemos onde está esse ponto. Então, fazemos o seguinte:
Intuição geométrica:
- Calculamos a inclinação da curva (derivada) no ponto atual;
- Se a inclinação é positiva, descemos para a esquerda;
- Se é negativa, descemos para a direita;
- Repetimos até chegar ao ponto mais baixo.
A ideia é calcular a inclinação (gradiente) da função de custo e mover-se no sentido oposto, reduzindo o erro passo a passo.
Fórmula simples:
Seja \(w\) o peso e \(J(w)\) a função de custo (erro). A atualização é feita por:
\(w := w – \eta \cdot \frac{\partial J}{\partial w}\)
Onde:
- \(\eta\) é a taxa de aprendizado (learning rate);
- \(\frac{\partial J}{\partial w}\) é o gradiente — a direção de maior crescimento do erro (derivada do erro em relação a cada peso);
- O sinal “−” indica que andamos na direção contrária ao erro.
Como isso se aplica a redes neurais?
Em uma rede com muitos neurônios e camadas, cada peso influencia o erro de forma diferente. Então, precisamos descobrir como cada peso contribuiu para o erro total. É aí que entra o algoritmo de retropropagação.
Backpropagation (retropropagação do erro)
Nas redes com múltiplas camadas, o cálculo do gradiente é feito de trás para frente, através do algoritmo de retropropagação do erro (backpropagation) (RUMELHART; HINTON; WILLIAMS, 1986), que aplica a regra da cadeia para propagar o erro e ajustar cada peso proporcionalmente à sua contribuição.
(1) Feedforward
- Enviamos os dados de entrada através da rede;
- Calculamos as saídas e o erro final (função de custo).
(2) Backpropagation
- Calculamos o quanto cada neurônio contribuiu para o erro;
- Atualizamos os pesos proporcionalmente a essa contribuição.
Ou seja:
Cada peso recebe um “puxão” para se mover na direção que reduz o erro.
Intuição visual:
Pense em uma bola rolando em um vale. A bola é o conjunto de pesos, e o vale é a função de custo. O gradiente descendente é a força que empurra a bola para o fundo (mínimo global). A retropropagação é o método que calcula para onde empurrar cada parte da bola (cada peso individualmente).
O ciclo completo de aprendizado
Para cada época (passagem completa pelo conjunto de dados):
- Entrada → passa pela rede (feedforward)
- Saída → calcula o erro
- Backpropagation → ajusta os pesos
- Repetimos até o erro estabilizar ou atingir um limite mínimo
Desafios do gradiente descendente
- Taxa de aprendizado muito alta → pula o mínimo e não converge.
- Taxa muito baixa → demora para aprender.
- Mínimos locais → pode “preso” em pontos que não são o menor erro possível.
- Explosão/Desaparecimento do gradiente → em redes muito profundas, o gradiente pode se tornar grande demais ou pequeno demais.
Esses problemas foram os principais desafios das redes neurais nos anos 90 — e só com técnicas como ReLU, normalização e otimizadores modernos (Adam, RMSProp) é que o Deep Learning decolou de verdade.
Implementação do Perceptron do zero
Antes de usar frameworks como TensorFlow ou PyTorch, é essencial entender o que acontece por baixo dos panos. Essas bibliotecas automatizam cálculos complexos, mas se você não entender o mecanismo base, o aprendizado se torna superficial.
Ao implementar um Perceptron do zero, você vai:
- Consolidar o entendimento teórico — compreender como a rede ajusta os pesos com base no erro.
- Perceber a lógica interna de uma rede neural: produto escalar, soma, função de ativação e atualização de pesos.
- Ganhar base sólida para entender redes maiores e mais profundas (MLP, CNN, RNN etc.).
Em outras palavras:
Implementar do zero é o primeiro passo para deixar de ser um usuário de redes neurais e começar a entendê-las de verdade.
Abaixo, um exemplo simples de implementação do Perceptron em Python com NumPy, incluindo visualização da fronteira de decisão e gráfico de erro.
# -----------------------------------------------------------
# Implementação do Perceptron do zero (em NumPy)
# Autor: Davi Teixeira
# Disciplina: Deep Learning (Módulo 0 — Fundamentos)
# -----------------------------------------------------------
import numpy as np
import matplotlib.pyplot as plt
# -----------------------------------------------------------
# 1. Gerando dados de exemplo
# -----------------------------------------------------------
# Vamos criar um conjunto de dados simples de classificação binária
# Exemplo: porta lógica OR
# Entradas (X) e saídas esperadas (y)
X = np.array([
[0, 0],
[0, 1],
[1, 0],
[1, 1]
])
y = np.array([0, 1, 1, 1]) # saída da porta lógica OR
# -----------------------------------------------------------
# 2. Inicializando pesos e hiperparâmetros
# -----------------------------------------------------------
np.random.seed(42) # para reprodutibilidade
weights = np.random.rand(2) # pesos aleatórios (um para cada entrada)
bias = np.random.rand() # bias inicial
learning_rate = 0.1 # taxa de aprendizado
epochs = 10 # número de iterações (épocas)
# -----------------------------------------------------------
# 3. Função de ativação
# -----------------------------------------------------------
# O perceptron original usa uma função de ativação degrau:
# Se a soma ponderada >= 0 → saída 1
# Caso contrário → saída 0
def step_function(x):
return 1 if x >= 0 else 0
# -----------------------------------------------------------
# 4. Processo de treinamento
# -----------------------------------------------------------
errors_per_epoch = [] # armazenar erro total por época
for epoch in range(epochs):
total_error = 0
for i in range(len(X)):
# Calcula a soma ponderada das entradas
linear_output = np.dot(X[i], weights) + bias
# Passa pela função de ativação
y_pred = step_function(linear_output)
# Calcula o erro (diferença entre o esperado e o previsto)
error = y[i] - y_pred
# Atualiza os pesos e o bias com base no erro
weights += learning_rate * error * X[i]
bias += learning_rate * error
# Soma o erro absoluto (para monitorar o desempenho)
total_error += abs(error)
errors_per_epoch.append(total_error)
# Exibe o progresso a cada época
print(f"Época {epoch+1}/{epochs} - Erro total: {total_error}")
# -----------------------------------------------------------
# 5. Visualização do erro ao longo das épocas
# -----------------------------------------------------------
plt.figure(figsize=(6, 4))
plt.plot(range(1, epochs + 1), errors_per_epoch, marker='o')
plt.title("Erro total por época (Treinamento do Perceptron)")
plt.xlabel("Época")
plt.ylabel("Erro total")
plt.grid(True)
plt.show()
# -----------------------------------------------------------
# 6. Fronteira de decisão
# -----------------------------------------------------------
# Criar uma grade de pontos no plano (x1, x2)
x_min, x_max = -0.5, 1.5
y_min, y_max = -0.5, 1.5
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 100),
np.linspace(y_min, y_max, 100))
# Para cada ponto da grade, calcula a saída do perceptron
Z = np.array([step_function(np.dot(np.array([x, y]), weights) + bias)
for x, y in zip(np.ravel(xx), np.ravel(yy))])
Z = Z.reshape(xx.shape)
# -----------------------------------------------------------
# 7. Plot da fronteira de decisão
# -----------------------------------------------------------
plt.figure(figsize=(6, 6))
plt.contourf(xx, yy, Z, alpha=0.3, cmap=plt.cm.Paired)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', cmap=plt.cm.Paired, s=100)
plt.title("Fronteira de decisão aprendida pelo Perceptron")
plt.xlabel("x1")
plt.ylabel("x2")
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.grid(True)
plt.show()
# -----------------------------------------------------------
# 8. Teste do modelo treinado
# -----------------------------------------------------------
print("\n--- Testando o Perceptron ---")
for i in range(len(X)):
linear_output = np.dot(X[i], weights) + bias
y_pred = step_function(linear_output)
print(f"Entrada: {X[i]} → Saída prevista: {y_pred}")
# -----------------------------------------------------------
# 9. Pesos finais aprendidos
# -----------------------------------------------------------
print("\nPesos finais:", weights)
print("Bias final:", bias)
Explicação resumida do que o código faz
- Criamos um dataset simples (porta lógica OR).
- Inicializamos pesos e bias com valores aleatórios.
- Definimos a função de ativação (degrau).
- Treinamos o modelo ajustando pesos e bias com base no erro.
- Testamos o modelo para ver se aprendeu a regra da OR.
- Gráfico do erro ao longo das épocas, mostrando se o perceptron está realmente aprendendo;
- Fronteira de decisão (decision boundary), para visualizar como ele separa as classes no plano 2D.
- Exibimos os pesos finais aprendidos.
Durante o treinamento, a rede aprende que qualquer entrada com pelo menos um “1” deve gerar saída 1.
Interpretação dos resultados
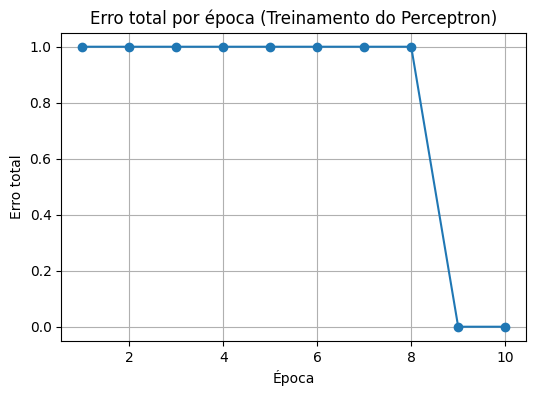
Você verá o erro total diminuindo ao longo das épocas — indicando aprendizado. Como o problema da porta OR é linearmente separável, o perceptron converge rapidamente.
Como o problema da porta OR é linearmente separável, o perceptron converge rapidamente.
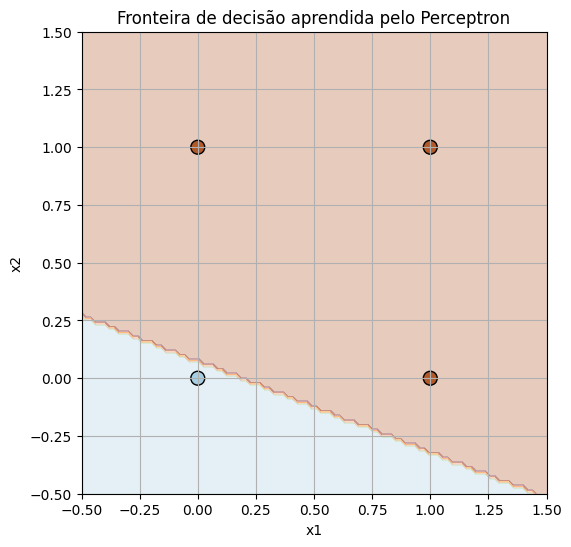
Cada ponto do dataset (as bolinhas) será colorido conforme sua classe real. A área colorida representa onde o perceptron prevê cada classe.
Essa parte visual é fundamental para criar intuição geométrica sobre como redes neurais aprendem:
- O gráfico de erro mostra a evolução temporal do aprendizado.
- A fronteira de decisão mostra a geometria do que foi aprendido.
Essas duas visões — temporal e espacial — são as bases para entender por que redes mais profundas são necessárias quando o problema não é linearmente separável (como no XOR).
Por que implementamos isso?
Implementar o Perceptron do zero é um rito de passagem para quem estuda Deep Learning. Ele mostra, na prática, como uma máquina aprende a partir dos erros.
Mesmo sendo um modelo simples, ele contém os princípios fundamentais que sustentam as redes neurais modernas:
- Representar entradas como vetores numéricos;
- Calcular combinações lineares com pesos e bias;
- Aplicar uma função de ativação;
- Ajustar pesos com base no erro (aprendizado supervisionado).
Ou seja, o que o Perceptron faz manualmente, redes neurais profundas fazem em larga escala — com milhões de neurônios, várias camadas, e funções de custo complexas, mas seguindo a mesma lógica.
O problema XOR — quando o Perceptron falha
Apesar de elegante, o Perceptron falha completamente no problema XOR (ou “ou exclusivo”), pois esse problema não é linearmente separável. Esse fato foi criticamente exposto por Minsky e Papert (1969), levando a um período de estagnação conhecido como o “inverno das redes neurais”.
Entrada \(x_1\) |
Entrada \(x_2\) |
Saída \(y\) |
|---|---|---|
0
|
0
|
0
|
0
|
1
|
1
|
1
|
0
|
1
|
1
|
1
|
0
|
A regra é:
A saída é 1 somente se exatamente uma das entradas for 1.
Por que o Perceptron falha no XOR?
O Perceptron é um classificador linear. Isso significa que ele só consegue traçar uma reta (em 2D) para separar as classes. Mas o problema do XOR não é linearmente separável.
Se plotarmos os pontos no plano, veremos isso:
- (0,0) → classe 0
- (1,1) → classe 0
- (0,1) e (1,0) → classe 1
Esses pontos estão dispostos em formato de “X”, ou seja, não há uma reta que os separe corretamente.
Testando o Perceptron no problema XOR
Vamos reutilizar o código anterior, só trocando os dados para o problema XOR.
# -----------------------------------------------------------
# Perceptron testado no problema XOR
# -----------------------------------------------------------
import numpy as np
import matplotlib.pyplot as plt
# -----------------------------------------------------------
# 1. Dataset: porta lógica XOR
# -----------------------------------------------------------
X = np.array([
[0, 0],
[0, 1],
[1, 0],
[1, 1]
])
y = np.array([0, 1, 1, 0]) # XOR
# -----------------------------------------------------------
# 2. Inicialização dos parâmetros
# -----------------------------------------------------------
np.random.seed(42)
weights = np.random.rand(2)
bias = np.random.rand()
learning_rate = 0.1
epochs = 20
# -----------------------------------------------------------
# 3. Função de ativação (degrau)
# -----------------------------------------------------------
def step_function(x):
return 1 if x >= 0 else 0
# -----------------------------------------------------------
# 4. Treinamento
# -----------------------------------------------------------
errors_per_epoch = []
for epoch in range(epochs):
total_error = 0
for i in range(len(X)):
linear_output = np.dot(X[i], weights) + bias
y_pred = step_function(linear_output)
error = y[i] - y_pred
# Atualização
weights += learning_rate * error * X[i]
bias += learning_rate * error
total_error += abs(error)
errors_per_epoch.append(total_error)
print(f"Época {epoch+1}/{epochs} - Erro total: {total_error}")
# -----------------------------------------------------------
# 5. Gráfico do erro
# -----------------------------------------------------------
plt.figure(figsize=(6, 4))
plt.plot(range(1, epochs + 1), errors_per_epoch, marker='o')
plt.title("Erro total por época - XOR")
plt.xlabel("Época")
plt.ylabel("Erro total")
plt.grid(True)
plt.show()
# -----------------------------------------------------------
# 6. Fronteira de decisão
# -----------------------------------------------------------
x_min, x_max = -0.5, 1.5
y_min, y_max = -0.5, 1.5
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 100),
np.linspace(y_min, y_max, 100))
Z = np.array([step_function(np.dot(np.array([x, y]), weights) + bias)
for x, y in zip(np.ravel(xx), np.ravel(yy))])
Z = Z.reshape(xx.shape)
plt.figure(figsize=(6, 6))
plt.contourf(xx, yy, Z, alpha=0.3, cmap=plt.cm.Paired)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', cmap=plt.cm.Paired, s=100)
plt.title("Fronteira de decisão do Perceptron - XOR")
plt.xlabel("x1")
plt.ylabel("x2")
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.grid(True)
plt.show()
# -----------------------------------------------------------
# 7. Teste final
# -----------------------------------------------------------
print("\n--- Testando o Perceptron no XOR ---")
for i in range(len(X)):
linear_output = np.dot(X[i], weights) + bias
y_pred = step_function(linear_output)
print(f"Entrada: {X[i]} → Saída prevista: {y_pred}")
print("\nPesos finais:", weights)
print("Bias final:", bias)O que podemos observar
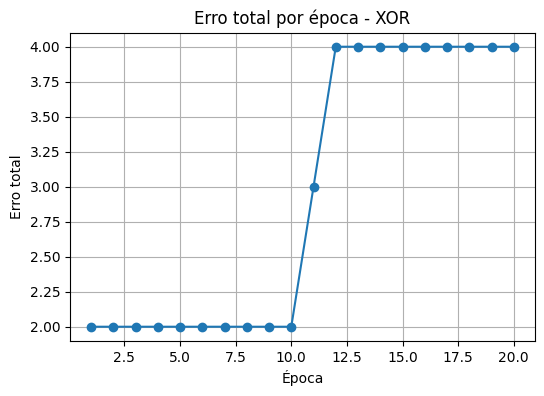
Erro nunca zera completamente — o perceptron não consegue convergir.
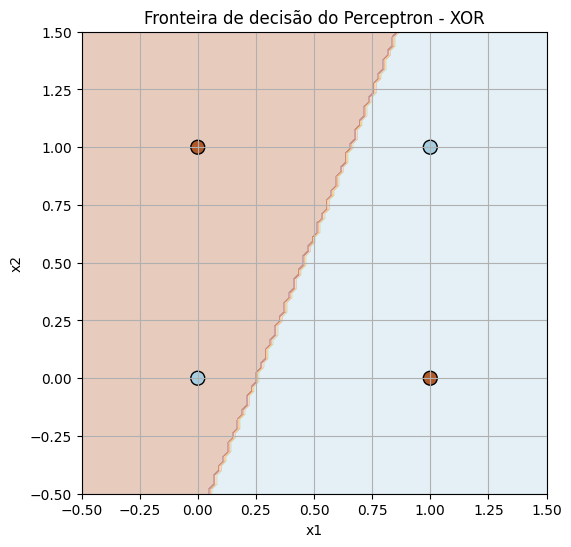
Fronteira de decisão (reta) separa apenas parte dos pontos corretamente.
Mesmo treinando por muitas épocas, duas amostras sempre serão classificadas erradas.
O fracasso do Perceptron e o nascimento da MLP
Esse fracasso foi um ponto histórico na IA. O Perceptron de Rosenblatt (1958) parecia promissor, mas em 1969, Minsky e Papert publicaram o livro Perceptrons, mostrando matematicamente que o modelo não podia resolver o XOR — nem qualquer outro problema não linearmente separável.
Isso levou a uma pausa nas pesquisas de redes neurais (o chamado “Inverno da IA”).
Mais tarde, na década de 1980, pesquisadores descobriram que, ao adicionar camadas intermediárias (ocultas) e usar o algoritmo de retropropagação do erro (backpropagation), a rede podia aprender relações não lineares complexas, como o XOR. Essas redes foram chamadas de Redes Neurais Multicamadas (MLP) — a base do Deep Learning moderno.
Conclusão
O Perceptron foi o primeiro neurônio artificial capaz de aprender com dados. Apesar de suas limitações, ele foi o ponto de partida de toda uma revolução tecnológica. Dele nasceram as redes multicamadas, e dessas redes surgiram arquiteturas cada vez mais sofisticadas — até chegarmos aos modelos modernos de Deep Learning.
Implementar o Perceptron do zero é mais do que um exercício de programação: é uma forma de compreender as engrenagens internas das redes neurais. Ao manipular pesos, bias, função de custo e observar o gradiente descendente em ação, você deixa de ver o Deep Learning como uma “caixa-preta” e passa a entendê-lo como um sistema matemático coerente e interpretável.
Esse entendimento será essencial à medida que avançarmos para arquiteturas mais complexas, como MLPs, CNNs e RNNs — que nada mais são do que extensões dessas ideias fundamentais.
Se você ainda não conhece os conceitos básicos, recomendo ler meu artigo sobre Fundamentos da Aprendizagem de Máquina.
Referências
- GOODFELLOW, Ian; BENGIO, Yoshua; COURVILLE, Aaron. Deep Learning. Cambridge: MIT Press, 2016.
- HAYKIN, Simon. Neural Networks and Learning Machines. 3rd ed. Pearson, 2009.
- MCCULLOCH, Warren; PITTS, Walter. A Logical Calculus of the Ideas Immanent in Nervous Activity. The Bulletin of Mathematical Biophysics, v. 5, n. 4, p. 115–133, 1943.
- MINSKY, Marvin; PAPERT, Seymour. Perceptrons: An Introduction to Computational Geometry. Cambridge: MIT Press, 1969.
- ROSENBLATT, Frank. The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain. Psychological Review, v. 65, n. 6, p. 386–408, 1958.
- RUMELHART, David; HINTON, Geoffrey; WILLIAMS, Ronald. Learning representations by back-propagating errors. Nature, v. 323, p. 533–536, 1986.
Compartilhe:
Você já tinha pensado que uma única linha reta — o limite do Perceptron — foi o que atrasou o avanço da IA por 20 anos? Como você acha que estaríamos hoje se Rosenblatt tivesse criado uma rede multicamada em 1958? Nos conte aqui nos comentários!