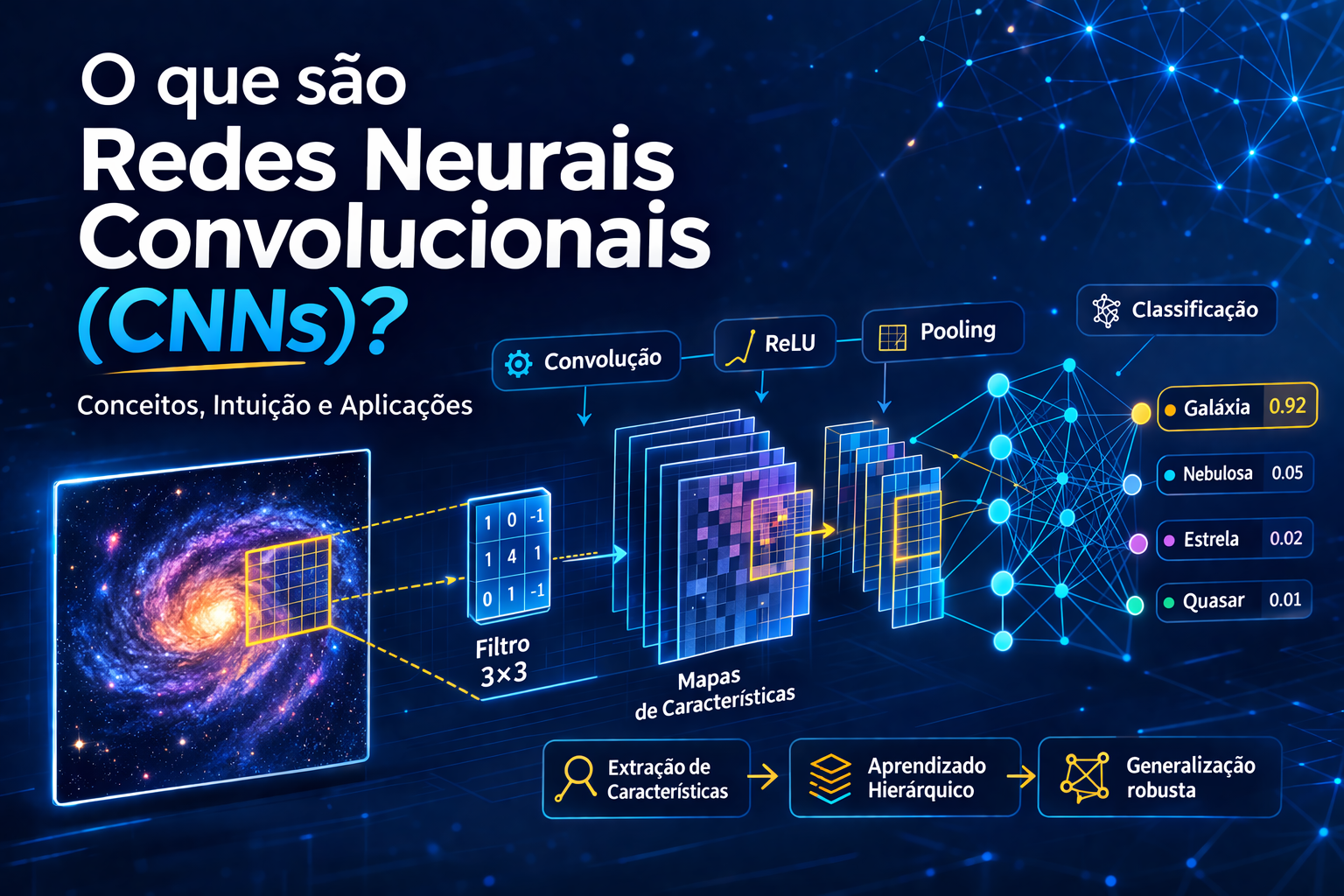
Este artigo explora as Redes Neurais Convolucionais (CNNs), arquiteturas fundamentais no deep learning projetadas especificamente para processar dados com estrutura de grade, como imagens. O texto aborda desde os princípios de localidade e compartilhamento de pesos até as inovações em arquiteturas residuais e escalonamento composto. O profissional técnico aprenderá como essas redes operam, os marcos de sua evolução histórica — incluindo a recente convergência com modelos Transformers — e como aplicar boas práticas para otimizar o desempenho em tarefas de visão computacional.
Se você ainda não viu os conceitos base, recomendo começar por meus artigos sobre fundamentos de Machine Learning e Deep Learning, pois eles dão o suporte teórico necessário para entender melhor os mecanismos discutidos aqui.
O que são Redes Neurais Convolucionais (CNN) e para que servem?
A década de 2010 marcou uma mudança de paradigma: deixamos o design manual de características (handcrafted features) para focar no design de arquiteturas de redes que aprendem sozinhas. O catalisador foi a AlexNet em 2012 (Krizhevsky et al., 2012), no emblemático ‘Momento ImageNet‘. O sucesso das CNNs reside em seus vieses indutivos, como a equivariância de translação, que permite ao modelo identificar padrões (como bordas ou texturas) independentemente de onde apareçam na imagem. Ou seja, a rede aprende que ‘um olho é um olho’, independentemente de onde ele aparece na imagem — o que elimina a necessidade de reaprender o mesmo padrão em posições diferentes. Hoje, elas evoluíram de simples classificadores de dígitos para o núcleo de sistemas complexos, como o diagnóstico médico por imagem e a navegação de veículos autônomos.
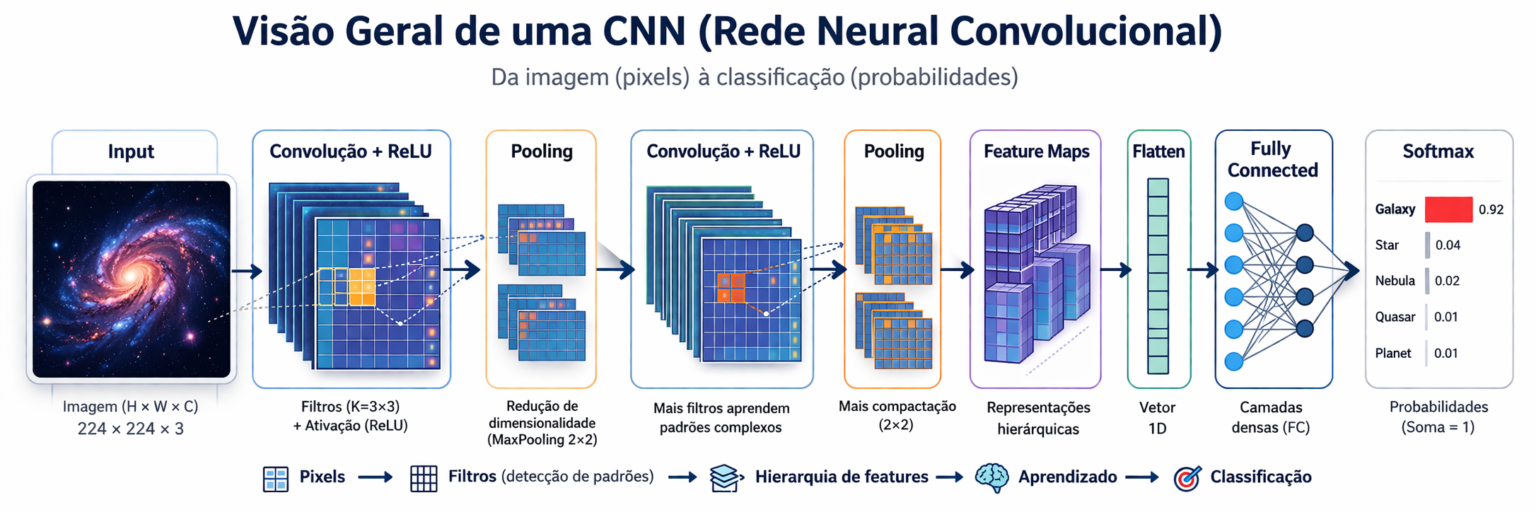
Figura 1: Visão geral da arquitetura de uma Rede Neural Convolucional (CNN). O fluxo ilustra a jornada dos dados desde a entrada da imagem (pixels) até a classificação final (probabilidades). Note como as camadas de Convolução e Pooling extraem características hierárquicas, que são “achatadas” (Flatten) e processadas por camadas densas (Fully Connected) para a tomada de decisão via Softmax.
Como funcionam as CNNs? Arquitetura e camadas explicadas.
1. O que é uma camada convolucional e o compartilhamento de pesos?
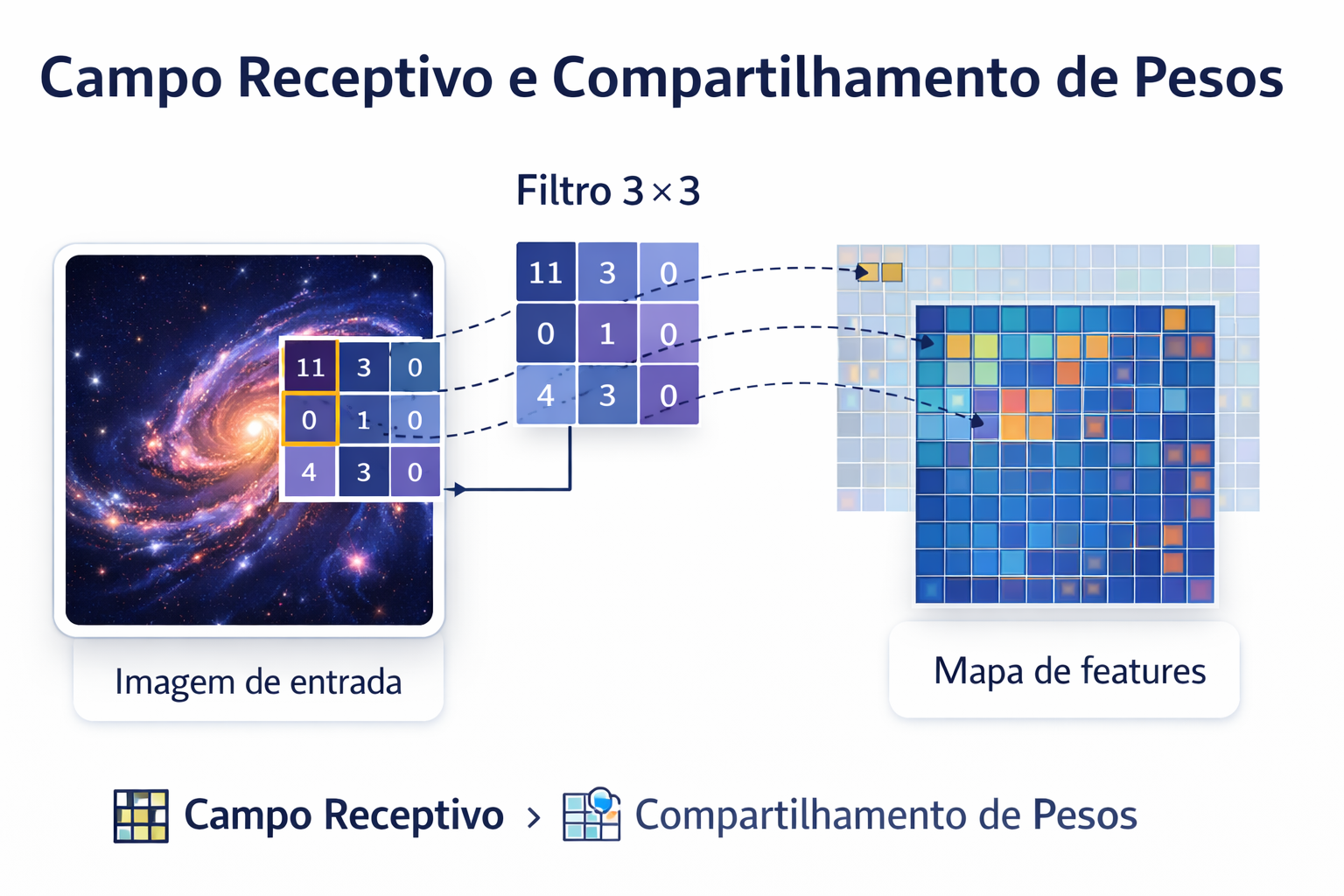
Figura 2: Esta ilustração detalha os conceitos de Campo Receptivo e Compartilhamento de Pesos. O filtro \(3 \times 3\) atua como uma janela deslizante que “varre” a imagem de entrada, multiplicando seus pesos pelos valores dos pixels locais. Esse processo gera o Mapa de Features, uma representação matemática que preserva a hierarquia espacial dos dados, permitindo que a rede reconheça características específicas — como bordas ou texturas — independentemente de onde apareçam na cena original.
Diferente das redes neurais densas, as CNNs exploram a localidade dos dados: pixels próximos possuem maior correlação entre si. Através do conceito de campo receptivo local, o mecanismo de “janela deslizante” (filtros convolucionais) aplica o mesmo detector de características em toda a imagem. Essa técnica, conhecida como compartilhamento de pesos, reduz drasticamente o número de parâmetros, facilitando o treinamento e permitindo que a rede aprenda padrões espaciais (como bordas e texturas) independentemente de sua posição.
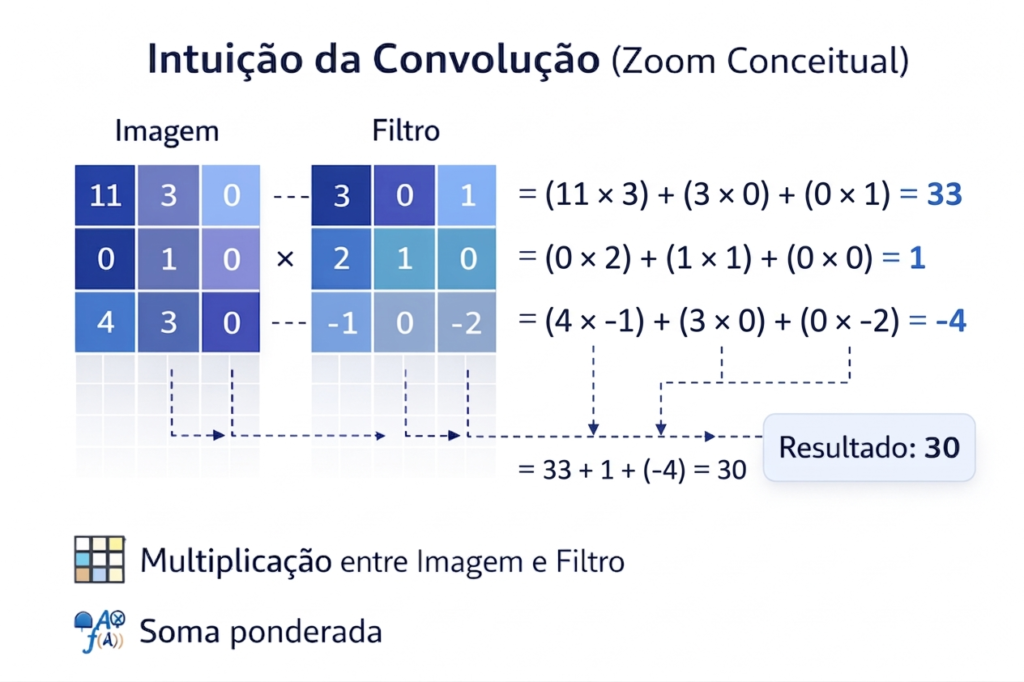
Figura 3: Para entender como a CNN extrai informação, precisamos olhar para a matemática básica. Esta ilustração demonstra o Zoom Conceitual da operação: o filtro sobrepõe a imagem e realiza uma Soma Ponderada. Esse valor único (neste exemplo, 30) condensa toda a informação daquela vizinhança de pixels em um novo mapa de características, preservando o que há de mais relevante para o reconhecimento do padrão.
2. O que é pooling e funções de ativação (ReLU vs GELU)?
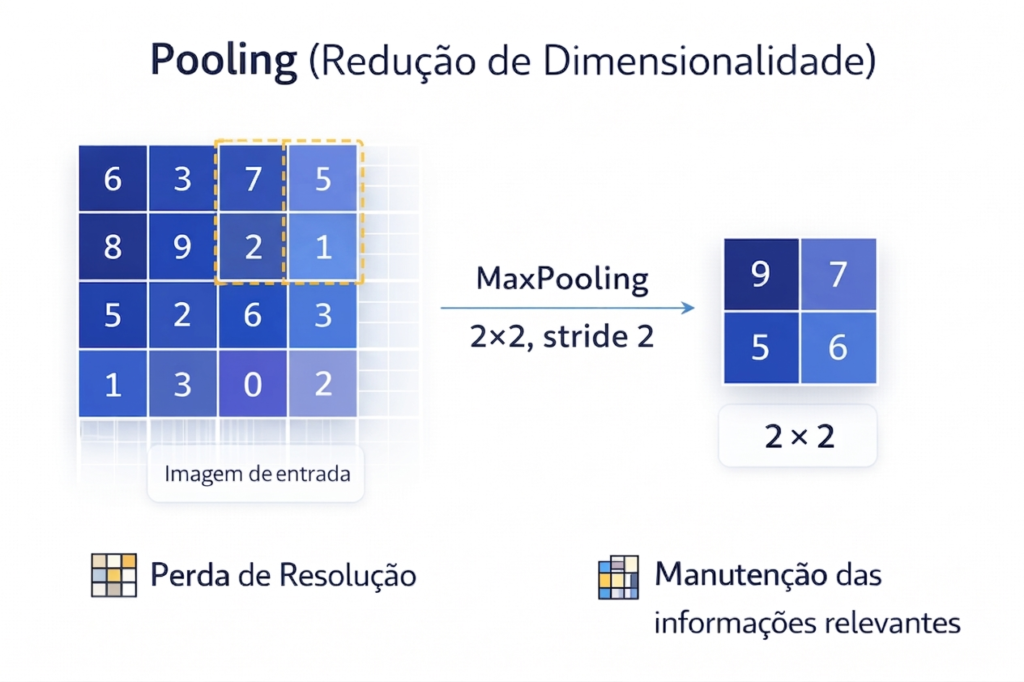
Figura 4: O MaxPooling atua como um filtro de relevância. Nesta ilustração, vemos como uma janela \(2 \times 2\) percorre a imagem e seleciona apenas o maior valor de cada região. Esse processo reduz drasticamente o custo computacional (redução de dimensionalidade) e ajuda a rede a focar nas características mais marcantes, tornando o sistema menos sensível a pequenas variações ou ruídos na posição dos objetos.
Com o aumento da profundidade das redes, a escolha da função de ativação passou a impactar diretamente a estabilidade do treinamento. Após a extração de padrões, a rede precisa de eficiência e não-linearidade:
- Pooling (Subamostragem): Reduz a resolução espacial da representação, diminuindo a sensibilidade do modelo a pequenas distorções e deslocamentos. O Max Pooling é o padrão para manter as características mais fortes.
- Funções de Ativação: Introduzem a capacidade de aprender relações complexas. Enquanto a ReLU revolucionou a área por ser rápida e simples, modelos de estado da arte migraram para a GELU (Gaussian Error Linear Unit). A GELU oferece uma curvatura mais suave, mitigando o problema de “neurônios mortos” e melhorando o fluxo do gradiente em arquiteturas profundas.
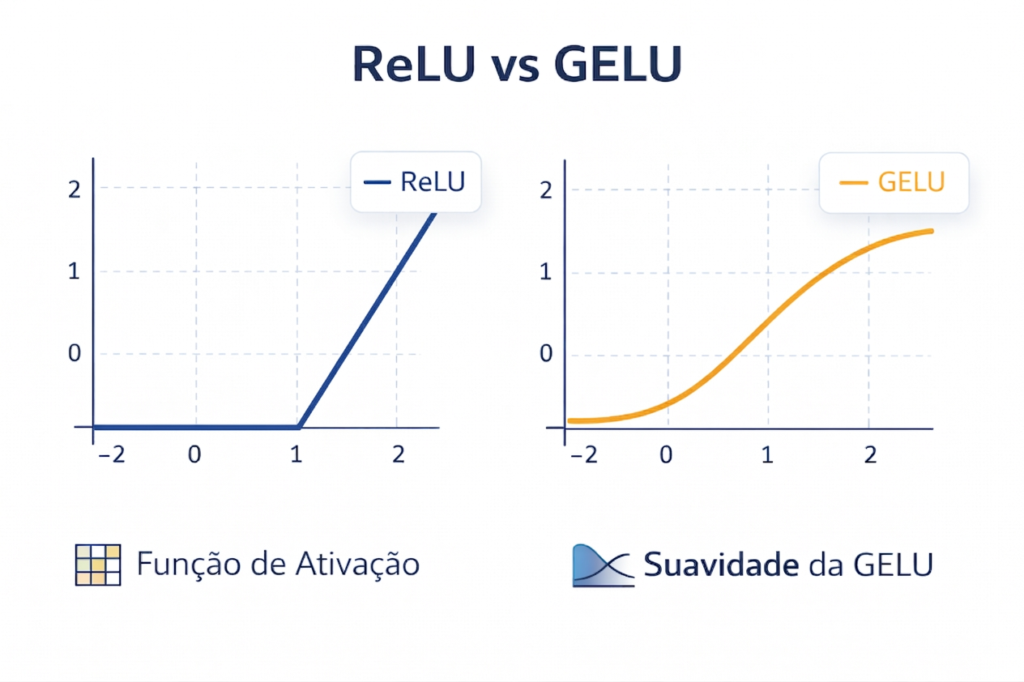
Figura 5: A escolha da função de ativação define como a rede aprende relações não-lineares. Enquanto a ReLU é eficiente e simples, sua “quebra” abrupta em zero pode causar o problema de neurônios mortos. A GELU (Gaussian Error Linear Unit), exibida à direita, resolve isso com uma curvatura suave, inspirada na distribuição normal, permitindo uma convergência mais estável em modelos de estado da arte que exigem alta precisão matemática.
3. O Problema da Degradação e o Aprendizado Residual
Historicamente, acreditava-se que apenas empilhar mais camadas aumentaria a precisão. No entanto, descobriu-se que redes muito profundas sofrem de degradação, onde o erro de treinamento aumenta de forma inesperada. A arquitetura ResNet (He et al., 2015) resolveu isso com as conexões de atalho (shortcut connections). Elas permitem que a rede aprenda funções residuais, garantindo que o gradiente flua sem impedimentos por centenas de camadas.
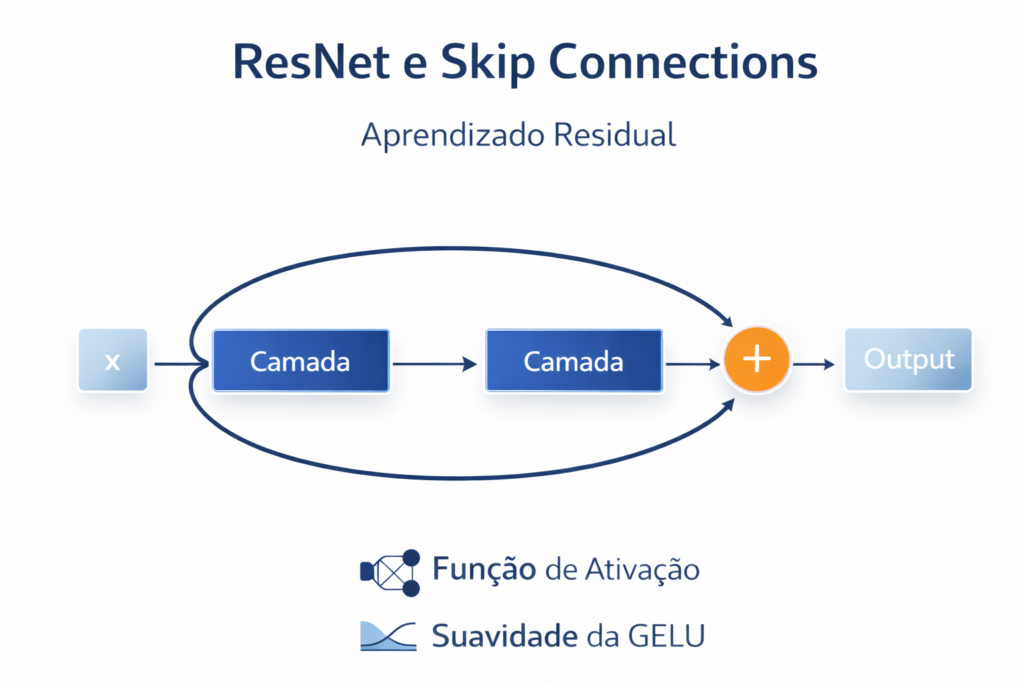
Figura 6: Para superar o limite de profundidade das redes convencionais, a ResNet introduziu o conceito de Skip Connections. Em vez de forçar a rede a aprender uma representação inteiramente nova em cada camada, essa arquitetura permite que ela aprenda apenas a diferença (o resíduo) necessária. Como vemos no diagrama, a entrada \(x\) “pula” as camadas através de um atalho, o que evita a perda de informação e permite o treinamento de modelos com centenas de camadas de forma estável.
4. Qual a diferença entre CNN e Vision Transformers (ViTs)?
Com o influente artigo An Image is Worth 16×16 Words (Dosovitskiy et al., 2020), os Transformers provaram que a atenção global poderia desafiar a hegemonia das convoluções. Porém, a principal diferença reside no viés indutivo. As CNNs possuem uma “crença inata” de que a informação é local (pixels vizinhos importam). Já os Vision Transformers tratam a imagem como uma sequência de retalhos (patches), utilizando o mecanismo de Atenção Global. Enquanto as CNNs são mais eficientes em conjuntos de dados menores por entenderem a estrutura espacial nativamente, os ViTs tendem a superá-las em bases de dados massivas, onde a relação entre pixels distantes pode ser aprendida do zero.
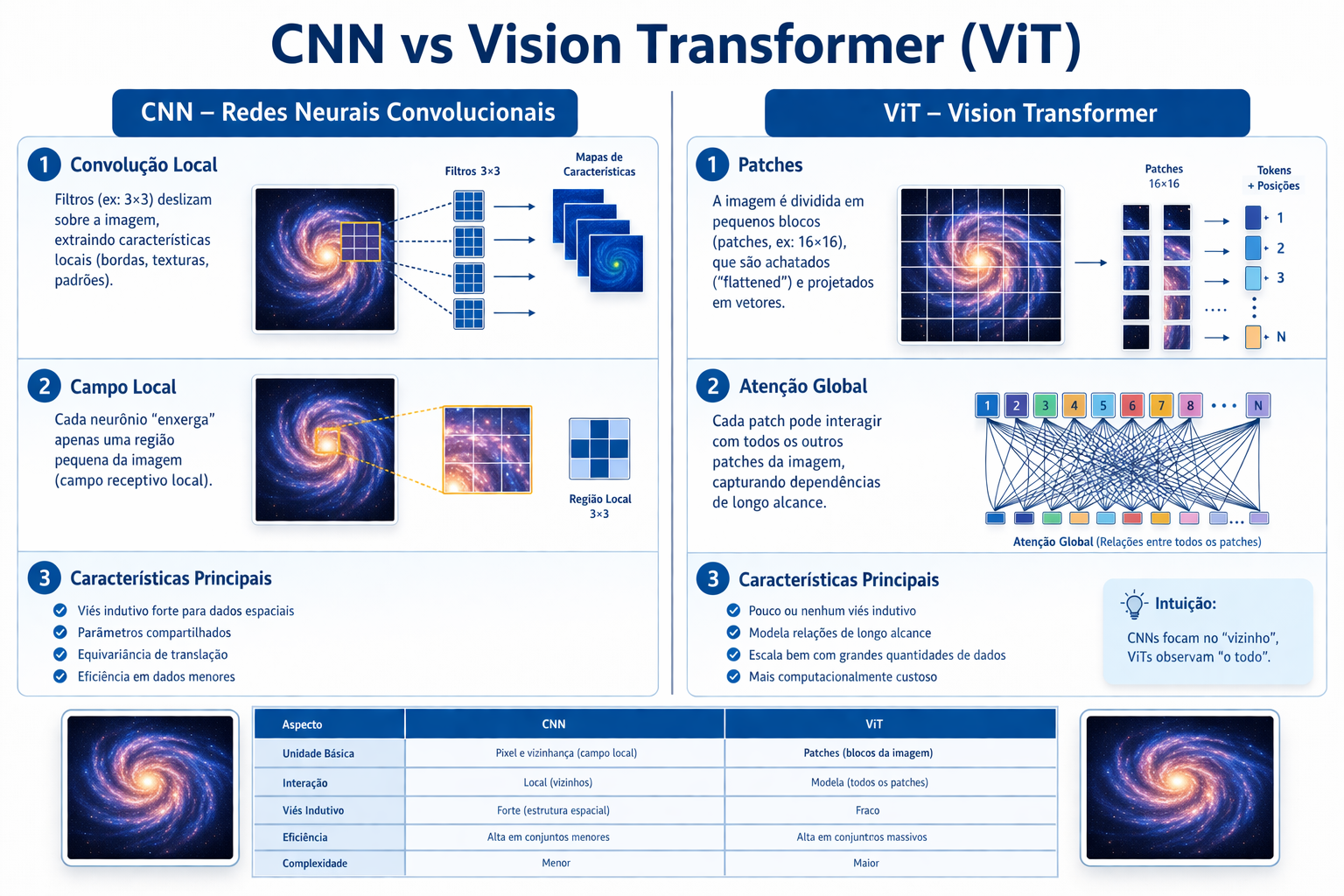
Figura 7: Entender a diferença entre CNNs e Vision Transformers (ViTs) é essencial para qualquer desenvolvedor de IA hoje. Enquanto as CNNs operam com um “viés indutivo” de localidade — assumindo que pixels próximos são mais importantes —, os ViTs quebram essa barreira ao tratar a imagem como uma sequência de blocos (patches) que podem interagir entre si globalmente. Como mostra o infográfico, essa diferença torna as CNNs imbatíveis em eficiência para bases menores, enquanto os ViTs brilham quando alimentados por volumes massivos de dados.
5. Como otimizar uma rede neural convolucional: Os modelos EfficientNet e ConvNeXt
A pesquisa evoluiu para entender como escalar redes de forma coordenada. O modelo EfficientNet (Tan & Le, 2019) demonstrou que é necessário equilibrar sistematicamente profundidade, largura e resolução da imagem para obter eficiência máxima. Recentemente, o trabalho A ConvNet for the 2020s (Liu et al., 2022) apresentou a arquitetura ConvNeXt, que “modernizou” as CNNs puras incorporando técnicas de design dos Transformers (como menos funções de ativação e normalização de camada), provando que as convoluções ainda competem em pé de igualdade com as novas tendências de atenção global.

Figura 8: Antes da EfficientNet, o escalonamento de redes era feito de forma arbitrária, aumentando apenas um dos eixos (como a profundidade na ResNet). Como demonstra a ilustração, o Compound Scaling propõe uma abordagem sistemática: para obter ganhos reais de precisão e eficiência, é preciso escalar a profundidade, a largura (canais) e a resolução da imagem de forma conjunta e proporcional. Essa estratégia permitiu criar modelos muito menores e mais rápidos que seus antecessores, mantendo um desempenho de estado da arte.
Exemplos Práticos
- Reconhecimento de Documentos: A LeNet-5 (LeCun et al., 1998) foi pioneira na leitura automatizada de cheques bancários, processando milhões de documentos diariamente com recordes de precisão, provando a viabilidade das CNNs em larga escala comercial.
- Classificação de Imagens em Larga Escala: Modelos como VGGNet e ResNet demonstraram superioridade em benchmarks como ImageNet, servindo como “backbones” para extração de características em diversas outras tarefas.
- Detecção e Segmentação: CNNs modernas (como a ConvNeXt) superam modelos baseados em atenção em tarefas complexas como detecção de objetos (benchmark COCO) e segmentação semântica (benchmark ADE20K) devido à eficiência das convoluções em processar altas resoluções.
Boas Práticas e Recomendações
1. Recomendações Importantes
- Aumento de Dados (Data Augmentation): Abuse de rotações, espelhamentos e ajustes de cor (color jittering) para forçar o modelo a aprender a essência do objeto, evitando o overfitting.
- Normalização: Use Batch Normalization para acelerar o treino em redes clássicas, mas considere Layer Normalization para designs modernos que buscam maior estabilidade e similaridade com Transformers.
- Regularização: Técnicas como Dropout em camadas densas e Stochastic Depth (descarte de camadas) em redes residuais são cruciais para a generalização.
2. Erros Comuns
- Escalonamento Desequilibrado: Não aumente apenas a profundidade. Siga a lição da EfficientNet: escale largura, profundidade e resolução de forma coordenada.
- Subestimar o Custo Computacional: Modelos hiper-densos aumentam a pegada de carbono e o custo de infraestrutura. Sempre avalie se uma arquitetura menor (como MobileNet) atende aos requisitos de negócio.
- Uso de Filtros Gigantes: Evite filtros grandes (ex: 7×7 ou 11×11). A VGGNet (Simonyan & Zisserman, 2014) provou que empilhar múltiplos filtros 3×3 oferece o mesmo campo de visão com menos parâmetros e mais camadas de ativação, tornando a rede mais expressiva.
Mão na Massa: Implementando uma Convolução
Para entender o poder das CNNs, vamos comparar uma implementação manual da operação de convolução usando NumPy com a implementação de alto desempenho utilizando PyTorch.
Antes de confiar em frameworks, é importante entender o que realmente está acontecendo por baixo dos panos.
1. Implementação com NumPy
Nesta implementação, simulamos o comportamento de um filtro (kernel) deslizando sobre uma imagem para extrair características. O foco aqui é entender a soma ponderada que ocorre em cada “janela” da imagem.
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
def convolution2d(image, kernel):
img_h, img_w = image.shape
kernel_h, kernel_w = kernel.shape
out_h, out_w = img_h - kernel_h + 1, img_w - kernel_w + 1
output = np.zeros((out_h, out_w))
for i in range(out_h):
for j in range(out_w):
region = image[i:i+kernel_h, j:j+kernel_w]
output[i, j] = np.sum(region * kernel)
return output
# 1. Criando uma imagem sintética com padrões (Bordas Horizontais e Verticais)
image = np.zeros((50, 50))
image[10:40, 10:25] = 255 # Bloco branco à esquerda
image[10:40, 25:40] = 128 # Bloco cinza à direita
# 2. Definindo Filtros de Sobel (Detectores de Bordas)
sobel_v = np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]]) # Vertical
sobel_h = np.array([[-1, -2, -1], [0, 0, 0], [1, 2, 1]]) # Horizontal
# 3. Aplicando a Convolução
edge_v = convolution2d(image, sobel_v)
edge_h = convolution2d(image, sobel_h)
# 4. Visualização Profissional
sns.set_theme(style="white")
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
# Imagem Original
axes[0].imshow(image, cmap='gray')
axes[0].set_title("Imagem Original (Input)", fontsize=12)
axes[0].axis('off')
# Borda Vertical
axes[1].imshow(np.abs(edge_v), cmap='viridis') # Usamos abs para destacar a variação
axes[1].set_title("Detector de Bordas Verticais", fontsize=12)
axes[1].axis('off')
# Borda Horizontal
axes[2].imshow(np.abs(edge_h), cmap='magma')
axes[2].set_title("Detector de Bordas Horizontais", fontsize=12)
axes[2].axis('off')
plt.tight_layout()
plt.show()
Na Figura 9, observamos como os filtros de Sobel destacam as mudanças bruscas de intensidade.
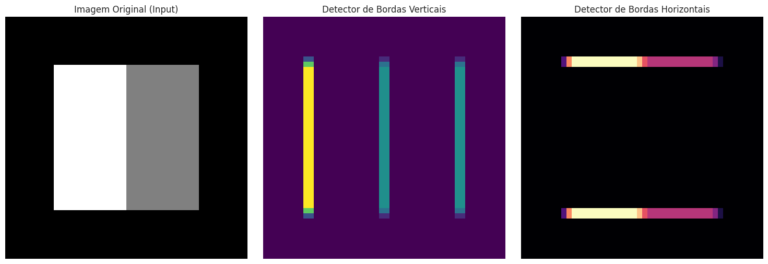
O detector vertical “acende” nas três linhas de transição lateral do quadrado, enquanto o horizontal captura apenas as bases superior e inferior. Note que o filtro ignora as áreas de cor sólida; ele só reage onde existe uma transição (gradiente), provando que a convolução é, essencialmente, um detector de variações espaciais.
2. Versão com PyTorch
No PyTorch, a operação é vetorizada e integrada à arquitetura de redes neurais, permitindo processar múltiplos filtros simultaneamente com alto desempenho.
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
# 1. Criando uma imagem realística (um quadrado branco no centro)
image_np = np.zeros((224, 224))
image_np[50:170, 50:170] = 1.0
# Convertendo para o formato do PyTorch [Batch, Channel, H, W]
input_tensor = torch.from_numpy(image_np).unsqueeze(0).unsqueeze(0).float()
# 2. Definindo a CNN e "Forçando" filtros conhecidos (Sobel)
class VisualCNN(nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Conv2d(1, 2, kernel_size=3, padding=1, bias=False)
# Filtro Vertical (Sobel)
sv = torch.tensor([[-1., 0., 1.], [-2., 0., 2.], [-1., 0., 1.]])
# Filtro Horizontal (Sobel)
sh = torch.tensor([[-1., -2., -1.], [0., 0., 0.], [1., 2., 1.]])
# Inserindo os pesos manualmente na camada
with torch.no_grad():
self.conv.weight[0, 0] = sv
self.conv.weight[1, 0] = sh
def forward(self, x):
return self.conv(x)
model = VisualCNN()
activations = model(input_tensor).detach()
# 3. Plotagem
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
titles = ["Entrada (Imagem)", "Filtro Vertical (PyTorch)", "Filtro Horizontal (PyTorch)"]
imgs = [image_np, activations[0, 0], activations[0, 1]]
cmaps = ['gray', 'viridis', 'magma']
for i in range(3):
axes[i].imshow(imgs[i], cmap=cmaps[i])
axes[i].set_title(titles[i], fontsize=13, pad=10)
axes[i].axis('off')
plt.tight_layout()
plt.show()Na Figura 9, vemos o mesmo resultado obtido através do framework.

A diferença fundamental é que, em uma rede real, o algoritmo de backpropagation ajustará esses pesos automaticamente. A rede “aprenderá” sozinha se deve procurar por bordas, texturas ou cores para resolver a tarefa proposta.
Conclusão
As Redes Neurais Convolucionais continuam sendo o pilar da visão computacional devido à sua eficiência e fortes propriedades geométricas intrínsecas. Embora os Vision Transformers tenham desafiado o trono da visão computacional, a evolução para modelos como a ConvNeXt reafirma que o paradigma convolucional é resiliente e altamente adaptável aos novos tempos.
Para o profissional de IA, mais do que decorar arquiteturas, o segredo está em dominar os fundamentos — da localidade de dados ao compartilhamento de pesos. Entender os fundamentos é o que permite construir sistemas de reconhecimento visual que sejam verdadeiramente robustos, escaláveis e precisos. No fim, CNNs não são apenas algoritmos que enxergam — são sistemas que aprendem a interpretar o mundo visual a partir de padrões, erros e generalizações.
Referências
- Zhuang Liu et al. (2022). A ConvNet for the 2020s.
- Kaiming He et al. (2015). Deep Residual Learning for Image Recognition.
- Mingxing Tan & Quoc V. Le (2019). EfficientNet: Rethinking Model Scaling.
- Yann LeCun et al. (1998). Gradient-Based Learning Applied to Document Recognition.
- Alex Krizhevsky et al. (2012). ImageNet Classification with Deep CNNs.
- Simonyan & Zisserman (2014). Very Deep CNNs for Large-Scale Image Recognition.
- Alexey Dosovitskiy et al. (2020). An Image is Worth 16×16 Words.
Compartilhe:
Gostou do conteúdo? Se este guia te ajudou a entender como as Redes Neurais Convolucionais transformam simples pixels em reconhecimento visual inteligente — do NumPy ao PyTorch — compartilhe este artigo! Ajude mais pessoas a dominarem a arquitetura que é a base da visão computacional moderna.