
Este artigo explora a regressão logística, um pilar da estatística e do aprendizado de máquina para tarefas de classificação binária e multiclasse. Diferente da regressão linear, este modelo utiliza a função logística para mapear preditores em probabilidades, permitindo uma interpretação estatística robusta dos resultados. Ao longo deste guia, abordaremos desde a fundamentação matemática e métodos de otimização até recomendações práticas para mitigar problemas comuns, como o overfitting.
O que é Regressão Logística e para que serve?
A regressão logística é um dos algoritmos mais utilizados na ciência de dados, sendo aplicada em campos que variam da medicina ao marketing e finanças. Embora compartilhe o termo “regressão”, sua finalidade principal é a classificação, relacionando variáveis de entrada a rótulos categóricos discretos.
Sua grande vantagem reside na capacidade de fornecer não apenas uma decisão binária, mas a probabilidade de um evento ocorrer. Essa característica a torna indispensável em cenários onde a incerteza precisa ser quantificada para a tomada de decisão.
Muitos problemas reais em ciência de dados não envolvem prever números, mas sim classificar eventos. Alguns exemplos comuns incluem:
- Detecção de fraude: Identificar transações suspeitas em tempo real.
- Diagnóstico médico: Estimar a probabilidade de uma patologia com base em exames.
- Filtros de Spam: Classificar e-mails como indesejados ou legítimos.
- Marketing Digital: Prever a propensão de clique (CTR) de um usuário em um anúncio.
Esse tipo de tarefa é conhecido como problema de classificação.
Qual a diferença entre Regressão Linear e Regressão Logística?
Embora compartilhem uma base matemática comum, a finalidade de ambos os modelos é distinta. Enquanto a Regressão Linear é projetada para prever valores contínuos (como o preço de um imóvel), a Regressão Logística foca em estimar a probabilidade de uma observação pertencer a uma classe específica.
A transição da regressão linear para a logística é a progressão pedagógica clássica no Machine Learning, e por um motivo claro: a regressão logística funciona como uma extensão conceitual da linear, adaptada para problemas de classificação.
A lógica por trás dessa adaptação é elegante e direta:
- Regressão Linear: O output é uma combinação linear dos preditores que pode assumir qualquer valor real (\(-\infty \) a \(+\infty \)).
- Regressão Logística: O modelo mantém a estrutura linear, mas utiliza uma função de ativação (Sigmoide) para mapear essa saída em um intervalo restrito entre 0 e 1, representando a probabilidade do evento.
Portanto, a regressão logística continua sendo um modelo linear, mas com a camada adicional da função logística para transformar outputs contínuos em decisões categóricas.
Como funciona a Regressão Logística?
As Limitação da Regressão Linear para Classificação
Imagine o desafio de prever se um e-mail é spam (1) ou legítimo (0). À primeira vista, poderíamos tentar aplicar uma regressão linear tradicional:
\[
\hat{y} = \beta_0 + \beta_1 x
\]
No entanto, essa abordagem apresenta dois problemas fundamentais:
Intervalo de Saída Inválido: A regressão linear é projetada para prever valores contínuos que podem variar de \(-\infty \) a \(+\infty \). Em uma tarefa de classificação, o modelo pode gerar outputs como \(-0.7\) ou \(2.1\), valores que não possuem significado físico como probabilidades, as quais devem estar estritamente entre \(0\) e \(1\).
Sensibilidade a Outliers: A reta da regressão linear é extremamente sensível a novos dados (extrapolação). A inclusão de um único ponto distante pode alterar drasticamente a inclinação da reta, invalidando as classificações anteriores.
Para resolver essas limitações, precisamos de uma transformação que “esmague” qualquer valor real para dentro do intervalo \([0, 1]\). É aqui que entram a Função Sigmoide e o conceito de Logit.
A Função Sigmóide e o Logit
O componente central da regressão logística é a função sigmóide (ou logística), responsável por mapear qualquer valor real vindo da combinação linear dos preditores para o intervalo \([0, 1]\). Matematicamente, ela é definida como:
\[\sigma (a)=\frac{1}{1+e^{-a}}\]
A fundamentação matemática da função logística e sua aplicação em sequências binárias foi consolidada por Cox (1958), estabelecendo as bases para o que hoje conhecemos como regressão logística. Esta função apresenta um formato em “S” característico e possui propriedades fundamentais para a modelagem probabilística:
- Assíntotas: Valores muito negativos aproximam-se de \(0\), enquanto valores muito positivos aproximam-se de \(1\).
- Interpretação de Probabilidade: Ela transforma o preditor linear em uma probabilidade interpretável, onde o valor central (\(\sigma(0) = 0.5\)) serve como o ponto de equilíbrio da classificação.
O inverso dessa transformação é conhecido como Logit ou Log-Odds (logaritmo da razão de chances):
\[\text{logit}(p)=\ln \left(\frac{p}{1-p}\right)\]
Enquanto a sigmóide “esmaga” valores reais para o intervalo de probabilidade, o logit faz o caminho inverso, mapeando probabilidades de volta para o espaço linear. Essa relação é o que permite que a regressão logística mantenha uma estrutura linear internamente, mesmo lidando com saídas não lineares.
Modelagem Probabilística e o Preditor Linear
A regressão logística não é apenas uma ferramenta de classificação, mas um modelo estatístico baseado na distribuição de Bernoulli (\(P(Y=y) = p^y (1-p)^{1-y}\)), ideal para eventos com dois resultados possíveis (sucesso ou falha).
O coração do modelo é o preditor linear (\(\eta = \mathbf{w}^T \mathbf{x} + b\)), que combina os atributos de entrada com pesos específicos. A função sigmóide atua como a “ponte” que vincula essa combinação linear à probabilidade de o evento pertencer à classe positiva:
\[P(y=1\mid \mathbf{x})=\sigma (\mathbf{w}^{T}\mathbf{x}+b)\]
Nesta estrutura, a regressão logística modela linearmente o logaritmo da razão de chances (log-odds). Isso significa que, enquanto a probabilidade se comporta de forma não linear (em “S”), a relação entre os atributos e o logit é puramente linear:
\[\ln \left(\frac{p}{1-p}\right)=w_{0}+w_{1}x_{1}+\dots +w_{n}x_{n}\]
A base de álgebra linear e cálculo necessária para compreender o funcionamento interno dos modelos de aprendizado de máquina, incluindo a logística, é amplamente coberta em Deisenroth et al. (2020).
Decisão e Generalização
Após calcular a probabilidade, o modelo aplica um limiar de decisão (threshold). O padrão é \(0.5\): se \(P(y=1|\mathbf{x}) > 0.5\), a instância é classificada como positiva; caso contrário, como negativa.
Para cenários que envolvem mais de duas categorias (classificação multiclasse), a função sigmóide é generalizada pela função Softmax:
\[\text{softmax}(z_{i})=\frac{e^{z_{i}}}{\sum _{j=1}^{K}e^{z_{j}}}\]
Essa extensão garante que a soma das probabilidades de todas as \(K\) categorias seja exatamente igual a \(1\), permitindo uma interpretação probabilística consistente em problemas complexos.
Estimação, Otimização e Fronteira de Decisão
Os parâmetros do modelo são ajustados via Estimação por Máxima Verossimilhança (MLE), que busca os pesos (\(\theta \)) que maximizam a probabilidade de observar os dados reais. Na prática, esse problema de maximização é resolvido minimizando o negativo da log-verossimilhança, o que define a função de custo Log Loss:
\[J(\mathbf{w}) = -\frac{1}{m} \sum_{i=1}^{m} [y^{(i)} \log(\hat{y}^{(i)}) + (1 – y^{(i)}) \log(1 – \hat{y}^{(i)})]\]
Essa abordagem, fundamentada na relação entre modelos probabilísticos e teoria da informação, é detalhada por Bishop (2006) e Murphy (2021), cujas obras exploram profundamente o comportamento das distribuições de probabilidade nesse contexto.
A otimização pode ser feita por métodos de primeira ordem, como o Gradiente Descendente, ou por métodos de segunda ordem mais rápidos para este contexto, como o Mínimos Quadrados Iterativamente Re-ponderados (IRLS). No espaço de atributos, esse processo define uma fronteira de decisão linear (\(\mathbf{w}^T \mathbf{x} + b = 0\)), onde a classificação muda no ponto exato em que a probabilidade predita cruza o limiar de 0,5.
A Natureza da Função de Custo (Log Loss)
Enquanto a regressão linear utiliza o erro quadrático (MSE), a logística adota a Entropia Cruzada por sua capacidade de lidar com probabilidades. Em termos práticos, essa função mede a “distância” entre a previsão do modelo e o rótulo real, apresentando duas características fundamentais:
- Penalização Assimétrica: Ela penaliza exponencialmente previsões muito confiantes, porém erradas. Por exemplo, prever uma probabilidade de 0,99 para um evento que pertence à classe 0 gera um erro altíssimo.
- Calibragem: Essa sensibilidade força o modelo a ser honesto sobre sua incerteza, resultando em probabilidades bem calibradas em vez de apenas classificações binárias.
Treinamento com Gradiente Descendente
Diferente da regressão linear, que permite encontrar os parâmetros ótimos por meio de uma solução analítica direta (Equação Normal), a regressão logística exige métodos iterativos. Isso ocorre porque a função de custo Log Loss não possui uma solução de “forma fechada” para o ponto de mínimo.
O método mais comum para este treinamento é o Gradiente Descendente. O algoritmo ajusta os pesos do modelo progressivamente, seguindo o sentido oposto ao gradiente da função de custo para minimizar o erro. A atualização dos parâmetros ocorre através da regra:
\[\mathbf{w}\leftarrow \mathbf{w}-\alpha \nabla J(\mathbf{w})\]
Onde:
- \(\alpha \) (Taxa de Aprendizado): Controla o tamanho do passo em cada iteração.
- \(\nabla J(\mathbf{w})\) (Gradiente): Indica a direção de maior subida da função de custo; subtraí-lo garante que estamos “descendo” em direção ao erro mínimo.
Este processo é repetido até que o modelo converja, ou seja, até que os ajustes nos pesos se tornem insignificantes e o erro atinja um patamar estável.
Regressão Logística é classificação ou regressão?
Afinal, por que um algoritmo de classificação carrega “regressão” no nome? Essa dualidade é a origem de muita confusão, mas a explicação reside na mecânica interna do modelo.
Embora o objetivo final seja a categorização (atribuir um rótulo 0 ou 1), o modelo atua internamente realizando uma regressão sobre o logit (log-odds). Ou seja, ele estima uma função contínua — a probabilidade — antes de tomar uma decisão discreta.
Na prática, podemos dividir sua operação em duas etapas:
- Etapa de Regressão: O modelo calcula uma saída contínua (probabilidade entre 0 e 1) baseada na combinação linear dos atributos.
- Etapa de Classificação: Aplica-se um limiar (threshold) sobre essa saída para converter a probabilidade em uma decisão de classe.
Portanto, a regressão logística é um classificador linear que utiliza técnicas de regressão para fundamentar suas previsões probabilísticas.
Implementando a Regressão Logística do zero
Abaixo está um exemplo básico de regressão logística implementada com NumPy.
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
class RegressaoLogistica:
def __init__(self, lr=0.1, n_iters=1000, lambda_reg=0.01):
self.lr = lr
self.n_iters = n_iters
self.lambda_reg = lambda_reg # Parâmetro de Regularização L2
self.weights = None
self.bias = None
self.loss_history = []
def _sigmoid(self, z):
return 1 / (1 + np.exp(-z))
def fit(self, X, y):
n_samples, n_features = X.shape
self.weights = np.zeros(n_features)
self.bias = 0
for _ in range(self.n_iters):
# Modelo Linear + Sigmóide
model = np.dot(X, self.weights) + self.bias
y_pred = self._sigmoid(model)
# Cálculo da Log Loss (com regularização L2)
loss = -np.mean(y * np.log(y_pred + 1e-15) + (1 - y) * np.log(1 - y_pred + 1e-15))
loss += (self.lambda_reg / (2 * n_samples)) * np.sum(self.weights**2)
self.loss_history.append(loss)
# Gradientes (Derivadas da Log Loss + L2)
dw = (1 / n_samples) * np.dot(X.T, (y_pred - y)) + (self.lambda_reg / n_samples) * self.weights
db = (1 / n_samples) * np.sum(y_pred - y)
# Atualização dos parâmetros
self.weights -= self.lr * dw
self.bias -= self.lr * db
def predict_proba(self, X):
return self._sigmoid(np.dot(X, self.weights) + self.bias)
def predict(self, X, threshold=0.5):
return [1 if i > threshold else 0 for i in self.predict_proba(X)]
# Exemplo de uso
X = np.array([[1, 2], [2, 3], [3, 4], [4, 5], [1, 1], [5, 5]])
y = np.array([0, 0, 1, 1, 0, 1])
modelo = RegressaoLogistica(lr=0.1, n_iters=1000)
modelo.fit(X, y)
print(f"Pesos Finais: {modelo.weights}")
print(f"Probabilidades: {modelo.predict_proba(X)}")
# Configuração estética
sns.set_theme(style="whitegrid")
plt.figure(figsize=(10, 5))
# Plotando a história da Loss
plt.plot(modelo.loss_history, color='#2c3e50', linewidth=2.5, label='Log Loss (Custo)')
# Estética do gráfico
plt.title("Curva de Aprendizado: Minimização da Log Loss", fontsize=14, pad=15)
plt.xlabel("Iterações (Épocas)", fontsize=12)
plt.ylabel("Custo (Erro)", fontsize=12)
plt.fill_between(range(len(modelo.loss_history)), modelo.loss_history, color='#34495e', alpha=0.1)
plt.legend()
plt.show()
def plot_decision_boundary(X, y, model):
# Criando uma malha (grid) para pintar o fundo
h = .02 # tamanho do passo no mesh
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# Prevendo probabilidades para cada ponto do grid
Z = np.array(model.predict(np.c_[xx.ravel(), yy.ravel()]))
Z = Z.reshape(xx.shape)
plt.figure(figsize=(10, 6))
# Pintando a região de decisão
plt.contourf(xx, yy, Z, cmap=plt.cm.RdYlGn, alpha=0.3)
# Plotando os pontos reais
scatter = plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', s=100, cmap=plt.cm.RdYlGn, label="Dados Reais")
# Linha da fronteira (onde prob = 0.5)
# Equação: w1*x1 + w2*x2 + b = 0 => x2 = -(w1*x1 + b) / w2
x1_line = np.array([x_min, x_max])
x2_line = -(model.weights[0] * x1_line + model.bias) / model.weights[1]
plt.plot(x1_line, x2_line, ls="--", color="black", label="Fronteira de Decisão (P=0.5)")
plt.title("Fronteira de Decisão Linear", fontsize=14)
plt.xlabel("Atributo 1 (ex: Idade)", fontsize=12)
plt.ylabel("Atributo 2 (ex: Colesterol)", fontsize=12)
plt.legend()
plt.grid(alpha=0.3)
plt.show()
# Chamada da função
plot_decision_boundary(X, y, modelo)Após a execução do código acima, podemos observar dois comportamentos fundamentais do modelo. O primeiro é a Curva de Aprendizado (Figura 1), que valida a eficácia da nossa implementação do gradiente descendente. Note como a curva de perda (Log Loss) decai rapidamente nas primeiras iterações e depois atinge um patamar estável, sinalizando a convergência.
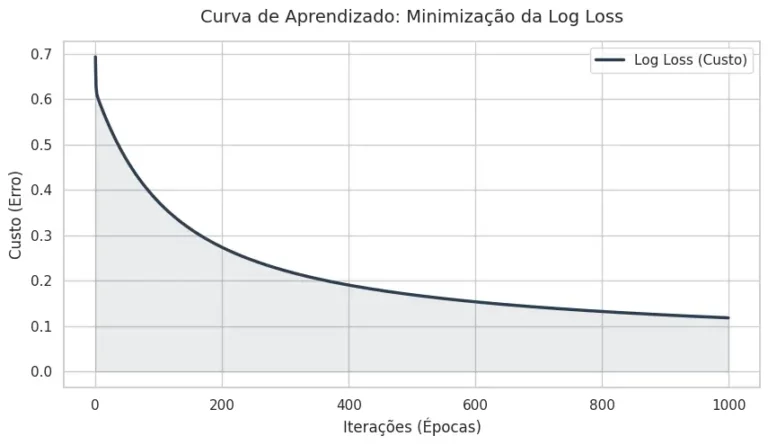
Figura 1: Minimização da função de custo (Log Loss) ao longo das iterações do Gradiente Descendente. O gráfico demonstra a convergência do modelo: à medida que as épocas avançam, o erro diminui e estabiliza, indicando que os pesos (\(\mathbf{w}\)) e o viés (\(b\)) encontraram um ponto de mínimo global.
Em seguida, projetamos a Fronteira de Decisão (Figura 2). Como a regressão logística é um classificador linear, ela projeta uma reta (hiperplano em dimensões maiores) que separa o espaço de características. Pontos que caem na região verde têm probabilidade \(> 0,5\) de pertencer à classe positiva, enquanto os na região vermelha estão abaixo desse limiar.
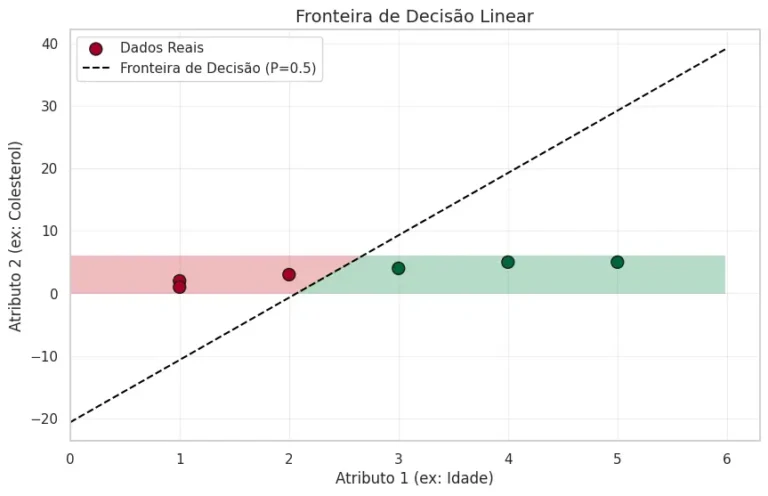
Figura 2: Representação visual da separação de classes no espaço de atributos. A linha tracejada indica o limiar onde a probabilidade predita é exatamente 0,5 (\(P=0.5\)). As áreas sombreadas em verde e vermelho representam as regiões de decisão onde o modelo classifica novos dados como positivos ou negativos, respectivamente.
Análise dos Hiperparâmetros
É importante notar que a suavidade da fronteira e a velocidade da queda da Loss não são fixas. Elas podem ser calibradas ajustando a Taxa de Aprendizado (\(\alpha \)) e o Parâmetro de Regularização (\(\lambda \)) que incluí no código.
- Um \(\alpha \) muito alto pode fazer o modelo “saltar” o ponto de mínimo, enquanto um muito baixo torna o treinamento excessivamente lento.
- Já o \(\lambda \) controla a complexidade: valores maiores forçam uma fronteira mais simples (menos propensa ao overfitting), enquanto valores próximos de zero permitem que o modelo se ajuste mais rigidamente aos dados de treino.
Versão com Scikit-Learn
Na prática, utilizamos bibliotecas otimizadas como o Scikit-learn. Ele abstrai a complexidade matemática e oferece ferramentas de diagnóstico integradas.
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix, classification_report, ConfusionMatrixDisplay
import matplotlib.pyplot as plt
import numpy as np
# 1. Dados (Os mesmos utilizados na implementação NumPy)
X = np.array([[1, 2], [2, 3], [3, 4], [4, 5], [1, 1], [5, 5]])
y = np.array([0, 0, 1, 1, 0, 1])
# 2. Implementação com Scikit-Learn
# penalty='l2' é o padrão (Ridge). C é o inverso da força de regularização (1/lambda)
modelo_sk = LogisticRegression(penalty='l2', C=1.0)
modelo_sk.fit(X, y)
# 3. Predições
y_pred = modelo_sk.predict(X)
y_proba = modelo_sk.predict_proba(X)
# 4. Resultados Técnicos
print(f"Coeficientes (Weights): {modelo_sk.coef_}")
print(f"Intercepto (Bias): {modelo_sk.intercept_}")
# 5. Visualização da Matriz de Confusão
plt.figure(figsize=(8, 6))
cm = confusion_matrix(y, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=['Classe 0', 'Classe 1'])
# Plot customizado para combinar com o estilo do seu blog
disp.plot(cmap='Blues', values_format='d')
plt.title("Matriz de Confusão: Scikit-Learn", fontsize=14, pad=15)
plt.grid(False) # Remover grid para melhor visualização da matriz
plt.show()
# 6. Relatório de Métricas (Para o seu Guia de Interpretação)
print("\nRelatório de Classificação:")
print(classification_report(y, y_pred))Com poucas linhas de código, podemos treinar, prever e avaliar modelos em datasets reais com alta performance.
Nota sobre as implementações: Você notará que os coeficientes do NumPy e do Scikit-Learn não são idênticos. Isso ocorre porque bibliotecas profissionais utilizam solvers de segunda ordem (como o L-BFGS) e possuem uma parametrização de regularização (\(C\)) que pode diferir da nossa implementação manual. No entanto, observe que ambos os modelos convergiram para a solução correta, separando as classes com 100% de precisão.
Em datasets muito pequenos ou perfeitamente separáveis, como o deste exemplo, é comum atingirmos acurácia máxima. Em cenários reais, o foco do analista deve ser a generalização do modelo para dados que ele ainda não viu.
Entendendo a Matriz de Confusão
Como podemos observar, no código com Scikit-Learn foi implementada uma Matriz de Confusão, que serve como o “raio-x” do desempenho do nosso classificador.

Figura 3: Esta ferramenta permite visualizar o desempenho do classificador: os elementos na diagonal principal representam os acertos (Verdadeiros Positivos e Verdadeiros Negativos), enquanto a diagonal secundária revela as falhas de classificação.
A Figura 3 acima detalha a relação entre as previsões do modelo e os valores reais:
- Eixo Vertical (True label): Representa as classes reais dos dados.
- Eixo Horizontal (Predicted label): Representa as classes que o modelo previu.
Neste cenário, observamos uma classificação perfeita: os números na diagonal principal (3 e 3) indicam que todos os exemplos da Classe 0 e da Classe 1 foram identificados corretamente. Já os valores zero na diagonal secundária confirmam a ausência de Falsos Positivos (quando o modelo prevê 1 para algo que é 0) e de Falsos Negativos (quando o modelo prevê 0 para algo que é 1), resultando na acurácia de 100% vista no relatório.
Guia de Interpretação: Coeficientes e Odds Ratio
Um dos maiores diferenciais da regressão logística em relação a modelos de “caixa-preta” (como Redes Neurais) é a sua alta interpretabilidade. Cada coeficiente (\(\beta \)) reflete o impacto de uma variável preditora sobre o log-odds do evento.
Para tornar essa interpretação amigável ao negócio, aplicamos a função exponencial ao coeficiente, obtendo a Razão de Chances (Odds Ratio):
\[\text{OR}=e^{\beta }\]
Como ler os resultados:
A análise do Odds Ratio nos diz como a chance do evento muda para cada unidade de aumento na variável preditora:
- \(e^{\beta} > 1\): Indica uma associação positiva. A chance do evento aumenta conforme a variável cresce.
- \(e^{\beta} < 1\): Indica uma associação negativa. A chance do evento diminui conforme a variável cresce.
- \(e^{\beta} = 1\): A variável não possui efeito significativo sobre a probabilidade do evento.
Exemplo Prático:
Se o coeficiente de uma variável (ex: “Anos de Experiência”) resulta em um \(e^{\beta} = 1.25\), interpretamos que, a cada ano adicional de experiência, a chance do evento ocorrer (ex: “Promoção”) aumenta em 25%, mantendo-se todas as outras variáveis constantes.
Essa interpretação rigorosa e a aplicação prática dos coeficientes são detalhadas por Hilbe (2016), cuja obra serve como referência essencial para analistas que buscam precisão estatística no tratamento de razões de chance.
Quais as principais aplicações da Regressão Logística no mercado?
A versatilidade da regressão logística a torna um padrão de indústria em diversos setores:
- Saúde: Modelagem de risco clínico, como a probabilidade de sobrevivência de pacientes cardíacos com base em indicadores como idade, histórico familiar e níveis de colesterol.
- Biologia: Classificação de espécies de flores (ex: dataset Iris) entre espécies como Setosa e Versicolor com base em medidas de sépalas e pétalas.
- Finanças: Ferramenta central no credit scoring para aprovação de empréstimos e na detecção em tempo real de transações fraudulentas.
- Marketing: Previsão de churn (cancelamento de serviços) e cálculo da propensão de compra ou clique em anúncios digitais.
- Inteligência Artificial: Atua como o “bloco de construção” fundamental de Redes Neurais, onde a função logística serve como a função de ativação de saída para classificadores binários.
Boas Práticas e Como Evitar o Overfitting
Para garantir que o modelo generalize bem para novos dados, algumas estratégias são indispensáveis:
- Regularização (L1 e L2): O uso de penalidades L1 (Lasso) ou L2 (Ridge) é altamente recomendado para mitigar o overfitting, especialmente em datasets com muitos atributos. Enquanto o L2 suaviza os pesos, o L1 pode realizar a seleção de variáveis, zerando coeficientes irrelevantes.
- Padronização de Atributos (Scaling): Escalar os dados para que tenham média zero e variância unitária acelera a convergência do Gradiente Descendente e garante que a regularização seja aplicada de forma justa a todas as variáveis.
- Verificação da Linearidade no Logit: A regressão logística assume que os preditores têm uma relação linear com o Logit (não com a probabilidade). Se essa premissa falhar, pode ser necessário aplicar transformações polinomiais ou o uso de splines.
- Tratamento de Dados Perfeitamente Separáveis: Se as classes puderem ser divididas perfeitamente por uma reta, os coeficientes da MLE tendem ao infinito, tornando o modelo instável. Nestes casos, a regularização é obrigatória para estabilizar os pesos.
Preparação de Dados e Cuidados Essenciais
Antes de iniciar o treinamento, a qualidade dos dados e sua representação são fundamentais para a estabilidade da Regressão Logística:
- Variáveis Categóricas: Devem ser convertidas em formatos numéricos, como o One-Hot Encoding, para que o modelo consiga processá-las matematicamente.
- Escalonamento (Scaling): A padronização dos dados (média 0, variância 1) é crucial para garantir a convergência rápida dos algoritmos de otimização e a aplicação justa da regularização.
- Multicolinearidade: Variáveis altamente correlacionadas entre si podem inflar a variância dos coeficientes, prejudicando a interpretação do impacto real de cada preditor.
- Dados Desbalanceados: Se uma classe for muito mais frequente que a outra, o modelo pode se tornar tendencioso. Nestes casos, técnicas de reamostragem (como SMOTE) ou o ajuste de pesos das classes são recomendados.
Métricas de Avaliação: Como Medir o Sucesso?
Diferente da regressão linear, onde usamos o MSE, na classificação avaliamos a qualidade das decisões e das probabilidades. As métricas mais comuns incluem:
Métrica |
O que mede? |
Quando priorizar? |
|---|---|---|
Acurácia
|
Proporção total de acertos.
|
Quando as classes estão bem balanceadas.
|
Precisão
|
De todos que classifiquei como positivo, quantos eram reais?
| |
Recall (Sensibilidade)
|
De todos os positivos reais, quantos o modelo encontrou?
|
Quando o custo de um Falso Negativo é crítico (ex: diagnóstico médico).
|
F1-Score
|
Média harmônica entre Precisão e Recall.
|
Quando buscamos um equilíbrio e as classes estão desbalanceadas.
|
AUC-ROC
|
Capacidade do modelo de separar as classes.
|
Para comparar modelos independentemente do limiar (threshold) escolhido.
|
O Papel da Matriz de Confusão
A base para quase todas as métricas acima é a Matriz de Confusão, uma tabela que cruza as previsões do modelo com os valores reais, permitindo visualizar onde o algoritmo está errando (se confunde a classe A com B ou vice-versa).
Um Breve Contexto Histórico
Embora seja um pilar do Machine Learning moderno, a função logística nasceu no século XIX, originalmente concebida para modelar o crescimento populacional. Foi apenas mais tarde que estatísticos perceberam seu potencial para mapear probabilidades de eventos binários.
Antes da ascensão do Deep Learning, a regressão logística era o padrão ouro em setores críticos como bancário, seguros e epidemiologia. Mesmo hoje, em uma era de modelos massivos, ela continua sendo uma escolha frequente devido à sua eficiência computacional e robustez. Em muitos cenários de produção, a simplicidade de um modelo bem calibrado ainda supera a “força bruta” de arquiteturas complexas.
Conclusão
A transição da regressão linear para a logística representa uma evolução elegante na história da estatística: aproveita-se a estrutura sólida de um modelo linear e, através de uma transformação matemática (a Sigmóide), adapta-se seu esqueleto para resolver problemas de classificação.
A regressão logística permanece indispensável por equilibrar três pilares fundamentais:
- Simplicidade: Baixo custo computacional e fácil implementação.
- Interpretabilidade: Ao contrário de modelos de “caixa-preta”, ela revela claramente o impacto de cada variável no resultado final.
- Fundamentação: É o ponto de partida essencial para compreender redes neurais e modelos avançados de classificação.
Dominar este algoritmo não é apenas aprender uma técnica de predição, mas sim adquirir a base necessária para quantificar a incerteza e tomar decisões orientadas a dados com confiança.
Referências
- BISHOP, Christopher M. Pattern Recognition and Machine Learning, 2006.
- COX, David R. The Regression Analysis of Binary Sequences, 1958.
- HILBE, Joseph M. Practical Guide to Logistic Regression, 2016.
- MURPHY, Kevin P. Probabilistic Machine Learning: An Introduction, 2021.
- DEISENROTH, Marc Peter et al. Mathematics for Machine Learning, 2020.
Compartilhe:
Gostou do conteúdo? Se este guia te ajudou a entender como a Regressão Logística transforma dados brutos em decisões probabilísticas inteligentes, compartilhe este artigo! Ajude mais pessoas a dominarem a base da classificação em Machine Learning.





