Quando começamos a estudar Machine Learning, um dos primeiros modelos que encontramos é a Regressão Linear. Ela aparece em praticamente todos os cursos e livros sobre ciência de dados porque resolve um problema muito comum: prever valores numéricos a partir de dados existentes.
Além de simples, a regressão linear representa o primeiro contato com o aprendizado supervisionado, servindo como base para compreender modelos mais complexos como Regressão Logística, SVM e Redes Neurais.
Este guia explora a regressão linear como uma ferramenta poderosa para avaliar a relação entre variáveis. Vamos detalhar seu funcionamento matemático, os principais métodos de otimização (como o Gradiente Descendente) e o uso de técnicas de regularização para garantir a precisão do modelo. Você aprenderá desde a distinção entre variáveis dependentes e independentes até a implementação prática, com foco em evitar problemas como o sobreajuste (overfitting).
Alguns exemplos simples incluem:
Imobiliário: Prever o valor de um imóvel com base em sua metragem e localização.
Vendas: Estimar a demanda futura de um produto para gestão de estoque.
Climatologia: Projetar variações de temperatura com base em séries históricas.
Apesar de parecer simples, a regressão linear introduz conceitos importantes que aparecem em praticamente todos os modelos de aprendizado de máquina, como:
Mapeamento de funções: Relacionar entradas (X) a saídas (y).
Funções de Custo: Como medir matematicamente o erro do modelo.
Otimização: O processo de “treinar” e ajustar pesos para minimizar falhas.
Generalização: A capacidade do modelo de performar bem em dados nunca vistos.
Neste artigo vamos entender como a regressão linear funciona, quando utilizá-la e como implementá-la na prática.
Por que aprender Regressão Linear?
Imagine que você deseja prever o preço de uma casa com base em seu tamanho (\(m^2\)). Você possui um conjunto de dados com pares de valores: tamanho e preço. O objetivo da regressão linear é encontrar a reta ideal que descreva a relação entre essas variáveis, permitindo projetar o valor de imóveis que ainda não entraram no mercado.
Essa relação pode ser expressa como:
\[
\hat{y} = \beta_0 + \beta_1 x
\]
onde cada termo desempenha um papel crucial:
- \( \hat{y} \) (Variável Dependente): É o valor que queremos prever (ex: o preço estimado da casa). O “chapéu” indica que se trata de uma estimativa, não do valor real exato.
- \(x\) (Variável Independente): É o atributo que usamos para a previsão (ex: o tamanho em (\(m^2\)).
- \( \beta_0 \) (Intercepto ou Bias): Representa o ponto onde a reta cruza o eixo vertical (\(y\)). Fisicamente, seria o valor base da previsão quando \(x = 0\).
- \( \beta_1 \) (Coeficiente Angular ou Peso): Determina a inclinação da reta. Ele indica o quanto o preço (\(y\)) tende a aumentar (ou diminuir) para cada unidade adicional de tamanho (\(x\)).
Fundamentos Teóricos
Historicamente, o conceito de regressão linear remonta ao início do século XIX com o Método dos Mínimos Quadrados, publicado por Legendre (1805) e Gauss (1809) para aplicações em astronomia e navegação. No final do século XIX, Sir Francis Galton introduziu o termo “regressão”, e em 1922, R.A. Fisher sintetizou a teoria moderna, unindo a teoria de erros de Gauss à teoria de correlação de Pearson. No contexto atual de aprendizado de máquina, a regressão linear é um pilar do aprendizado supervisionado devido à sua simplicidade, facilidade de interpretação e eficácia em cenários com dados esparsos ou baixo ruído.
1. Conceitos Fundamentais: O que você precisa saber
O objetivo central da regressão linear é encontrar uma função linear que mapeie as variáveis de entrada (preditores ou atributos) para uma variável de saída contínua (alvo ou resposta).
Em outras palavras, a ideia central é ajustar os parâmetros (\(\beta_0, \beta_1\)) de modo que a linha se aproxime o máximo possível dos pontos reais. O método mais comum para isso é o Método dos Mínimos Quadrados, que minimiza o Erro Quadrático Médio (MSE) entre os valores observados e os previstos:
\[
MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i – \hat{y}_i)^2
\]
A solução analítica dos parâmetros é dada por:
\[
{\beta} = (X^T X)^{-1} X^T y
\]
onde \(X\) é a matriz dos dados e \(y\) é o vetor de saídas. Essa expressão fornece a solução fechada do problema de mínimos quadrados.
- Variável Dependente (y): O valor real que o modelo tenta prever.
- Variáveis Independentes (x): As características utilizadas para a previsão.
- Parâmetros (coeficientes β): Coeficientes que determinam a influência de cada atributo no resultado final.
- Erro Residual (ϵ): A diferença entre o valor observado e o valor previsto, representando o ruído ou fatores não explicados.
Em termos simples, o algoritmo tenta encontrar a linha que passa o mais próximo possível de todos os pontos do dataset. Esse conceito é fundamental para entender muitos modelos mais avançados de Machine Learning.
2. Como funciona o ajuste de modelos lineares?
A regressão linear assume que a função de predição é uma combinação linear dos parâmetros, mesmo que as entradas passem por transformações não lineares. O ajuste do modelo é feito através de uma função custo, sendo a mais comum o Erro Quadrático Médio (MSE), que busca minimizar a soma dos quadrados das diferenças entre predições e valores reais.
\[
J(\beta) = \frac{1}{n} \sum_{i=1}^{n} (y_i – \hat{y}_i)^2
\]
3. Abordagens de Regressão: Simples, Múltipla e Polinomial
- Regressão Linear Simples: Utiliza apenas um único atributo para prever a saída.
- Regressão Linear Múltipla: Emprega dois ou mais preditores simultaneamente.
- Regressão Polinomial: Modela relações curvilíneas elevando os atributos a potências superiores, mantendo a linearidade nos parâmetros.
- Método dos Mínimos Quadrados Ordinários (OLS): Proporciona uma solução analítica fechada para encontrar os parâmetros ideais. Ou seja, Mesmo quando usamos polinômios \( ex: \hat{y} = \beta_0 + \beta_1 x + \beta_2 x^2 + \beta_3 x^3 + \epsilon \), o modelo ainda é linear nos parâmetros, pois os coeficientes continuam sendo combinados linearmente.
- Algoritmos Iterativos: Para grandes conjuntos de dados, utiliza-se:
- Gradiente Descendente (GD) que atualiza os parâmetros usando a média de todos os erros do conjunto de dados:
\[ \beta_{j} := \beta_{j} – \alpha \frac{1}{n} \sum_{i=1}^{n} (\hat{y}_i – y_i) x_{ij} \]
- Gradiente Descendente (GD) que atualiza os parâmetros usando a média de todos os erros do conjunto de dados:
- Gradiente Descendente Estocástico – SGD (ou regra de LMS – Least Mean Squares), que atualizam os pesos passo a passo para minimizar o custo, eliminando o somatório:
- \[ \beta_{j} := \beta_{j} – \alpha (\hat{y}_i – y_i) x_{ij} \]
Explicação dos termos:
- \( \beta_j \): O peso (parâmetro) que está sendo atualizado.
- \( \alpha \): A taxa de aprendizado (learning rate).
- \( (\hat{y}_i – y_i) \): O erro da predição (gradiente da função de custo).
- \( x_{ij} \): O valor do atributo \( j \) para a amostra \( i \). No caso da Regressão Polinomial, se você estiver atualizando o peso de
\( x^2 \), esse termo será \( x_i^2 \).
4. Regularização: Evitando Overfitting com Ridge e Lasso
Para controlar a complexidade e evitar que o modelo “decore” o ruído dos dados de treino, aplicam-se técnicas de penalização:
- Ridge Regression (L2): Adiciona o quadrado da magnitude dos coeficientes à função custo, reduzindo a variância em casos de multicolinearidade.
\[ J(\beta) = \frac{1}{n} \sum_{i=1}^{n} (y_i – \hat{y}_i)^2 + \lambda \sum_{j=1}^{m} \beta_j^2 \]
- Lasso (L1): Penaliza o valor absoluto dos coeficientes, podendo forçar alguns a zero, o que atua como uma técnica automática de seleção de variáveis.
\[ J(\beta) = \frac{1}{n} \sum_{i=1}^{n} (y_i – \hat{y}_i)^2 + \lambda \sum_{j=1}^{m} |\beta_j| \]
Explicação dos termos:
- \( \lambda \): O hiperparâmetro de regularização (controla a força da penalidade).
- \( \sum \beta_j^2 \): Penalidade \( L_2 \) (soma dos quadrados dos coeficientes).
- \( \sum |\beta_j| \): Penalidade \( L_1 \) (soma dos valores absolutos dos coeficientes).
Dica importante: No somatório da penalização (\( \sum \beta_j \)), geralmente começamos de \( j=1 \) (ignorando o intercepto \( \beta_0 \)), pois não costumamos penalizar o viés do modelo, apenas as inclinações.
Implementando a Regressão Linear do zero
Vamos implementar passo a passo o modelo em Python usando apenas NumPy, para entender o que acontece “por dentro” dos frameworks de ML. Como podemos observar na Figura 1, o modelo não tenta tocar todos os pontos, mas sim minimizar a distância quadrática total entre eles e a reta.
import numpy as np
import matplotlib.pyplot as plt
# 1. Gerando dados sintéticos mais realistas
np.random.seed(42)
X = 2 * np.random.rand(100, 1) * 50 + 40 # Tamanhos entre 40 e 140 m²
# Preço = 30 + 2.5 * Tamanho + ruído gaussiano
y = 30 + 2.5 * X + np.random.randn(100, 1) * 15
# 2. Preparação dos dados (Adicionando o Intercepto/Bias)
# Criamos uma matriz onde a primeira coluna é apenas 1s para o termo beta_0
X_b = np.c_[np.ones((100, 1)), X]
# 3. Equação Normal (O "Cérebro" do OLS)
# theta_best contém [beta_0, beta_1]
theta_best = np.linalg.inv(X_b.T @ X_b) @ X_b.T @ y
# 4. Cálculo da Margem de Erro (Desvio Padrão dos Resíduos)
y_treino_pred = X_b @ theta_best
erros = y - y_treino_pred
mse = np.mean(erros**2) # Erro Quadrático Médio (MSE)
# 5. Para a margem de erro no gráfico, usamos a raiz (RMSE)
# para que o erro fique em "mil R$" e não em "mil R$ ao quadrado"
margem = np.sqrt(mse)
# 6. Prever o valor médio exato do que foi gerado para testar
tamanho_teste = np.mean(X)
# 7. Cálculo usando a equação (beta0 + beta1 * X)
intercepto = theta_best[0][0]
coeficiente = theta_best[1][0]
preco_previsto = intercepto + (coeficiente * tamanho_teste)
# 8. Resultados
print(f"O modelo analisou {len(X)} imóveis.")
print(f"Equação encontrada: Preço = {intercepto:.2f} + {coeficiente:.2f} * Tamanho")
print(f"---")
print(f"Para uma casa de {tamanho_teste:.2f} m²:")
print(f"Cálculo: {intercepto:.2f} + ({coeficiente:.2f} * {tamanho_teste})")
print(f"Preço previsto pelo modelo: R$ {preco_previsto:.2f} mil")
print(f"Erro Quadrático Médio (MSE): {mse:.2f}")
print(f"Margem de Confiança (RMSE): ± {margem:.2f} mil R$")
# 9. Fazendo predições
X_new_line = np.array([[X.min()], [X.max()]]) # Garante que a linha cubra todos os pontos
y_predict_line = np.c_[np.ones((2, 1)), X_new_line] @ theta_best
# 10. Visualização (Gráfico)
plt.figure(figsize=(10, 6))
plt.scatter(X, y, color="#2ecc71", alpha=0.6, label="Dados Reais (com ruído)")
plt.plot(X_new_line, y_predict_line, color="#e74c3c", linewidth=3, label="Linha da Regressão")
# 11. Preenchendo a área de incerteza (1 desvio padrão para cima e para baixo)
plt.fill_between(X_new_line.flatten(),
(y_predict_line - margem).flatten(),
(y_predict_line + margem).flatten(),
color='#e74c3c', alpha=0.2, label="Margem de Erro (Confiança)", zorder=1)
# 12. Ponto que o modelo previu sozinho
plt.scatter(tamanho_teste, preco_previsto, color="black", s=200, marker='*', zorder=5, label="Predição Automática")
# 13. Estética do gráfico
plt.title("Ajuste de Regressão Linear: Preço vs Tamanho", fontsize=14)
plt.xlabel("Tamanho do Imóvel (m²)", fontsize=12)
plt.ylabel("Preço (mil R$)", fontsize=12)
plt.grid(True, linestyle='--', alpha=0.5)
plt.legend()
plt.show()Saída esperada:
- Intercepto e coeficiente exibidos no terminal;
- Gráfico mostrando a linha ajustada sobre os pontos de dados.
Ao executarmos o código acima, obtemos o seguinte gráfico, que ilustra a ‘Reta de Melhor Ajuste’ cruzando a nuvem de dados:
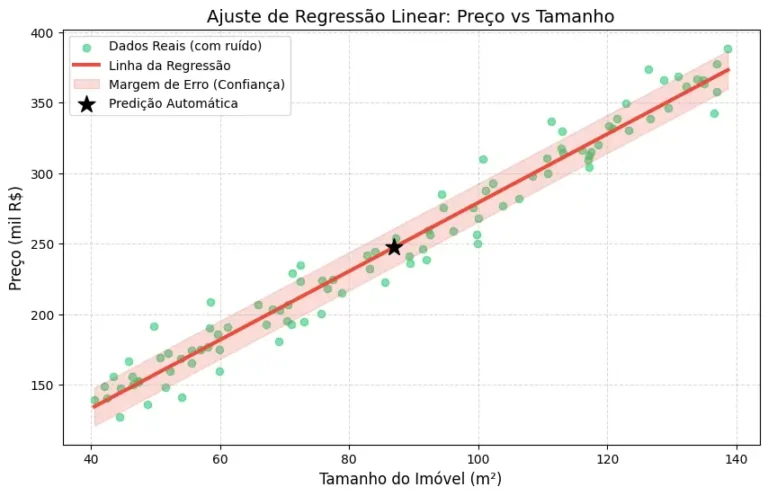
Figura 1: O gráfico acima ilustra o resultado do ajuste analítico por Mínimos Quadrados Ordinários (OLS). Observamos que a Linha da Regressão (em vermelho) corta com precisão a nuvem de Dados Reais (pontos verdes), capturando a tendência de crescimento do preço conforme o tamanho do imóvel aumenta
A Margem de Erro (área rosa), calculada a partir da raiz do Erro Quadrático Médio (MSE), define visualmente a zona de confiança do modelo; note que a grande maioria dos pontos com ruído reside dentro dessa faixa, o que valida a capacidade de generalização do algoritmo. O destaque em formato de estrela preta marca a predição exata para o tamanho médio da amostra (~87 m²), servindo como uma prova real de que o modelo aprendeu a representar o comportamento central do conjunto de dados.
Versão com Scikit-Learn
Após compreendermos a implementação matemática ‘do zero’ usando NumPy, utilizamos a biblioteca Scikit-Learn, o padrão da indústria para Machine Learning em Python.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 1. Dados (os mesmos do código anterior)
np.random.seed(42)
X = 2 * np.random.rand(100, 1) * 50 + 40
y = 30 + 2.5 * X + np.random.randn(100, 1) * 15
# 2. Implementação com Scikit-Learn
model = LinearRegression()
model.fit(X, y) # O sklearn já entende que X são os atributos e y é o alvo
# 3. Extraindo os parâmetros "aprendidos"
intercepto = model.intercept_[0]
coeficiente = model.coef_[0][0]
# 4. Cálculo do Erro usando as métricas do framework
y_pred_total = model.predict(X)
mse = mean_squared_error(y, y_pred_total)
margem = np.sqrt(mse)
# 5. Teste Automático (Valor Médio)
tamanho_teste = np.mean(X).reshape(-1, 1)
preco_previsto = model.predict(tamanho_teste)[0][0]
# 6. Resultados no Console
print(f"--- Versão Scikit-Learn ---")
print(f"Equação: Preço = {intercepto:.2f} + {coeficiente:.2f} * Tamanho")
print(f"Previsão para {tamanho_teste[0][0]:.2f} m²: R$ {preco_previsto:.2f} mil")
print(f"MSE: {mse:.2f}")
# 7. Visualização
X_new_line = np.array([[X.min()], [X.max()]])
y_predict_line = model.predict(X_new_line)
plt.figure(figsize=(10, 6))
plt.scatter(X, y, color="#3498db", alpha=0.6, label="Dados Reais")
plt.plot(X_new_line, y_predict_line, color="#e67e22", linewidth=3, label="Sklearn Regression")
# Área de Incerteza (Margem)
plt.fill_between(X_new_line.flatten(),
(y_predict_line - margem).flatten(),
(y_predict_line + margem).flatten(),
color='#e67e22', alpha=0.2, label="Margem (RMSE)")
plt.scatter(tamanho_teste, preco_previsto, color="black", s=200, marker='*', zorder=5, label="Predição Sklearn")
plt.title("Regressão Linear: Scikit-Learn vs Prática", fontsize=14)
plt.xlabel("Tamanho (m²)")
plt.ylabel("Preço (mil R$)")
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()Bibliotecas como o Scikit-Learn implementam versões altamente otimizadas desses algoritmos, permitindo aplicar o modelo em datasets maiores com poucas linhas de código. O código acima demonstra a eficiência do framework: com apenas três linhas (LinearRegression(), fit() e predict()), o algoritmo automatiza a adição do termo de bias (intercepto) e resolve a Equação Normal internamente como podemos ver na Figura 2.
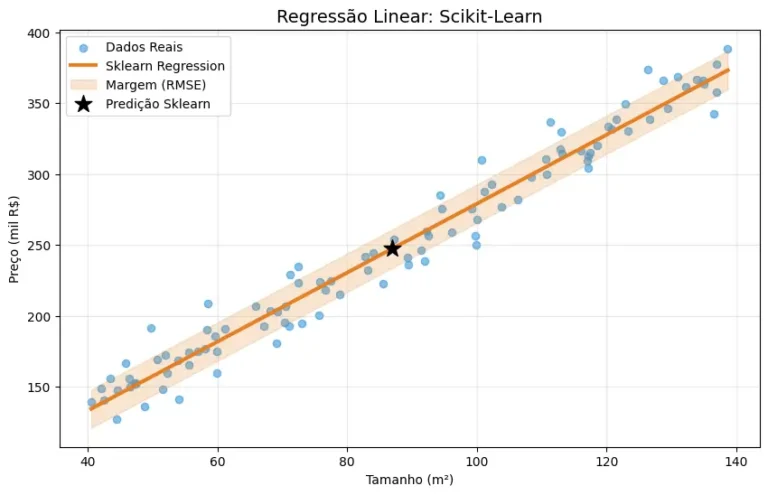
Figura 2: O gráfico acima ilustra o modelo final ajustado aos dados. A linha sólida laranja representa a função de predição aprendida pelo Scikit-Learn. A área sombreada ao redor da linha indica a margem de incerteza baseada no RMSE (raiz do MSE), evidenciando a dispersão natural dos dados reais (pontos azuis).
A principal vantagem de migrar do NumPy para o Scikit-Learn não é apenas a redução de código, mas a escalabilidade: este mesmo fluxo de trabalho pode ser aplicado para modelos com centenas de variáveis preditoras sem alteração na lógica fundamental. A facilidade de uso do framework permite integrar rapidamente a Margem (RMSE) de forma visual, representada pela área sombreada laranja. O destaque da estrela preta (Predição Sklearn) ilustra como o método .predict() facilita a estimativa de novos valores.
Por que, depois devemos avaliar o modelo?
Ajustar o modelo é apenas metade do trabalho. Precisamos saber se ele é confiável para fazer previsões em dados que ele nunca viu. Sem métricas, não sabemos se o modelo sofre de Underfitting (muito simples) ou Overfitting (decorou o ruído).
MSE (Erro Quadrático Médio):
Mede a “distância” média entre a previsão e o valor real. Como os erros são elevados ao quadrado, grandes desvios são penalizados severamente. Serve para comparar modelos: quanto menor o MSE, melhor. Ele é útil para identificar modelos que falham gravemente em pontos específicos.
\[
MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i – \hat{y}_i)^2
\]
R² (Coeficiente de Determinação):
É uma escala de 0 a 1 que diz o quanto o seu modelo é melhor do que um modelo que simplesmente chutasse a média para todo mundo. Serve para entender a qualidade do ajuste. Ele responde: “O quanto meu modelo é melhor que a média aritmética?”
\[R^2 = 1 – \frac{\sum (y_i – \hat{y}_i)^2}{\sum (y_i – \bar{y})^2}\]
- \( R^2 \approx 1 \): O modelo explica quase toda a variação.
- \( R^2 \approx 0 \): O modelo não é melhor do que chutar a média.
Exemplo de Implementação (Python):
y_pred_all = X_b @ theta_best
mse = np.mean((y - y_pred_all) ** 2)
r2 = 1 - (np.sum((y - y_pred_all)**2) / np.sum((y - np.mean(y))**2))
print(f"MSE: {mse:.2f}")
print(f"R²: {r2:.3f}")MAE (Erro Médio Absoluto)
O MAE (Mean Absolute Error) entra como o contraponto “robusto” ao MSE. Enquanto o MSE “pune” erros grandes (elevando ao quadrado), o MAE trata todos os erros proporcionalmente.
Ele é mais fácil de interpretar porque está na mesma unidade da sua variável \(y\) (ex: se você prevê preços em reais, o MAE te dá o erro médio em reais). Use o MAE quando você não quer que alguns poucos erros muito grandes distorçam a avaliação do modelo.
- Vantagem: Menos sensível a valores discrepantes que o MSE.
- Desvantagem: Matematicamente mais difícil de derivar (devido ao valor absoluto).
Exemplo de Implementação (Python):
mae = np.mean(np.abs(y - y_pred_all))
print(f"MAE: {mae:.2f}")
Resumo Comparativo:
- MSE: Bom para quando erros grandes são inaceitáveis.
- MAE: Bom para ter uma noção real do erro médio sem distorções de valores extremos.
- R²: Bom para saber a qualidade geral do modelo em relação a um “chute” básico.
Aplicações Reais
A regressão linear é amplamente usada em:
- Economia: prever preços, salários e crescimento de mercado;
- Engenharia: modelar relações físicas entre variáveis (ex: temperatura e pressão);
- Ciência de Dados: identificar tendências e relações entre variáveis;
- Saúde: estimar evolução de doenças ou eficácia de tratamentos.
Ela também serve como base conceitual para algoritmos mais avançados, como:
- Regressão Logística (para classificação);
- Redes Neurais (que generalizam funções lineares com não linearidades);
- SVMs e Modelos Probabilísticos.
Boas Práticas e Erros Comuns (Multicolinearidade e Outliers)
Recomendações Importantes
- Padronização dos Dados: É essencial escalar os atributos para que tenham média zero e variância unitária, especialmente ao usar métodos de regularização como Ridge ou Lasso.
- Validação Cruzada: Utilize esta técnica para selecionar hiperparâmetros de regularização e garantir a capacidade de generalização do modelo.
- Interpretação de Coeficientes: Tenha cautela ao interpretar a magnitude dos pesos, pois eles representam contribuições parciais e podem ser instáveis na presença de correlação entre variáveis.
- Verificar relação linear entre variáveis: A regressão linear funciona melhor quando existe uma relação aproximadamente linear entre as variáveis.
Erros Comuns e Cuidados
- Multicolinearidade: A correlação forte entre preditores infla a variância das estimativas, tornando o modelo sensível a pequenas mudanças nos dados.
- Extrapolação: Modelos de regressão são confiáveis apenas dentro do intervalo dos dados observados; previsões fora desse intervalo (extrapolação) têm alto risco de erro.
- Sensibilidade a Outliers: O método OLS é sensível a outliers, pois o erro quadrático amplifica observações muito distantes, o que pode exigir o uso de técnicas de regressão robusta.
Quando NÃO usar Regressão Linear
- Relações Não Lineares Complexas: O modelo falha em capturar padrões onde a relação entre variáveis não é aditiva, resultando em alto viés underfitting diante de fenômenos curvilíneos complexos.
- Alta Dimensionalidade: Em cenários onde o número de atributos excede o de amostras (\( p > n \)), o modelo tende ao overfitting extremo se não forem aplicadas técnicas de regularização.
- Presença de Outliers Críticos: A função de custo quadrática amplifica o impacto de valores discrepantes, exercendo uma força de alavancagem que distorce os coeficientes e prejudica a generalização.
Conclusão
Aprender Regressão Linear é como dar o primeiro passo na jornada do aprendizado supervisionado. Ela ensina o raciocínio fundamental de todo modelo preditivo: encontrar padrões e quantificar relações entre variáveis.
Ao implementarmos o modelo “na mão” com NumPy e depois utilizarmos o Scikit-Learn, percebemos que as ferramentas facilitam o trabalho, mas o conhecimento matemático é o que nos permite interpretar os resultados e confiar nas predições. Com esse entendimento, estamos prontos para avançar para modelos mais expressivos — como a Regressão Logística, que transforma previsões contínuas em classificações.
A regressão linear permanece como uma ferramenta indispensável. Embora simples em sua forma básica, suas extensões (como polinômios e regularização) permitem capturar nuances complexas nos dados mantendo a interpretabilidade. Compreender o equilíbrio entre viés e variância, além dos riscos da multicolinearidade, é o que transforma essa técnica estatística clássica em um modelo preditivo robusto e eficaz para o mundo real.
Referências
- A Review on Linear Regression Comprehensive in Machine Learning.
- LASSO (1996) – Robert Tibshirani.
- Bishop, C. M. Pattern Recognition and Machine Learning.
- Friedman et al. The Elements of Statistical Learning.
- Murphy, K. P. Machine Learning: A Probabilistic Perspective.
- Haykin, S. Neural Networks and Learning Machines.
- Montgomery et al. Introduction to Linear Regression Analysis.
- Deisenroth et al. Mathematics for Machine Learning.
- Fisher and Regression – Aldrich (2005).
- Gauss’ Method of Least Squares – Brand (2003).
- Ridge Regression – Hoerl & Kennard (1970).
Compartilhe:
Se este artigo te ajudou a desvendar a matemática por trás da Regressão Linear e como aplicá-la na prática, compartilhe com alguém que também está nessa jornada de dados!