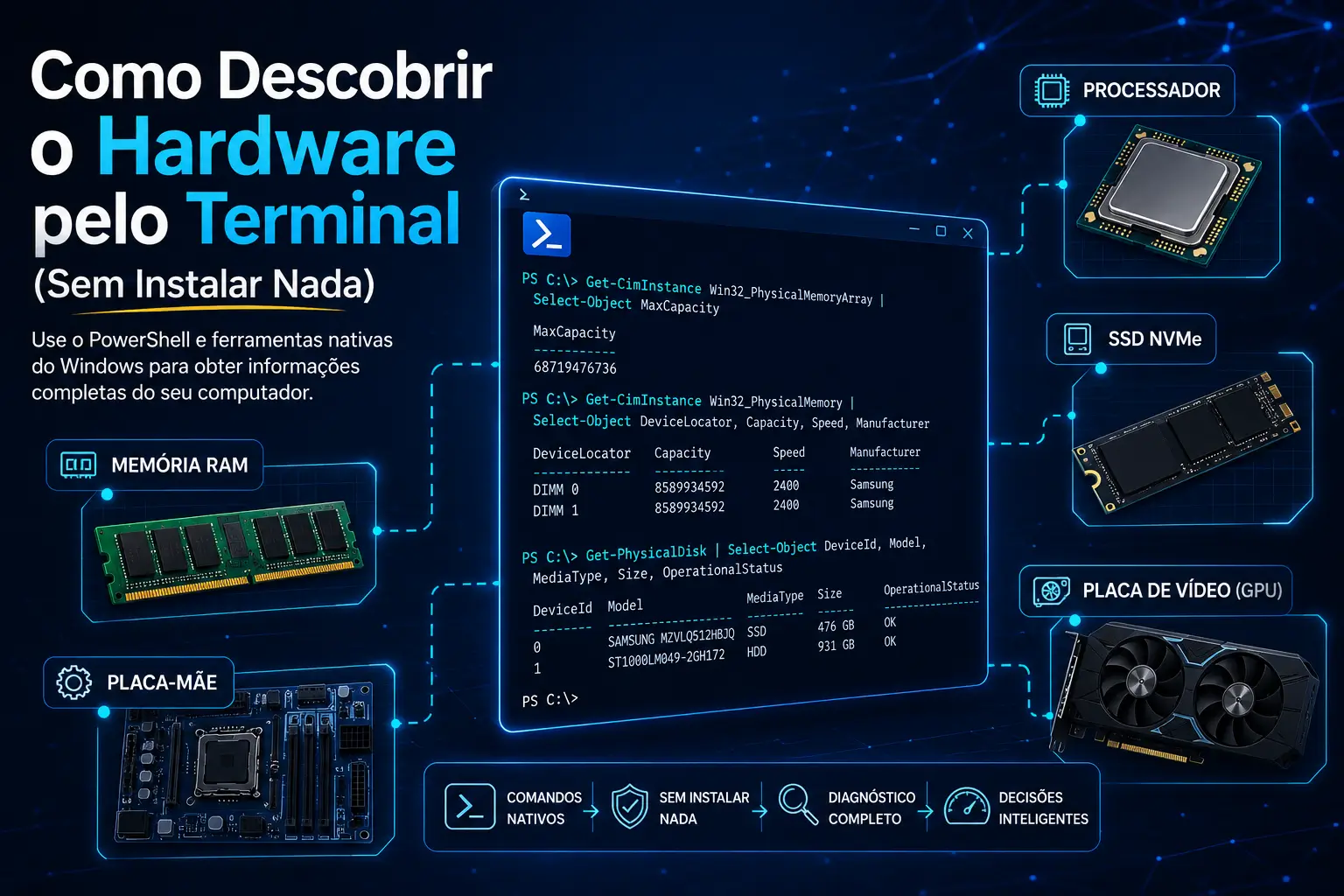
A análise exploratória de dados (EDA) é uma etapa crítica e inicial no ciclo de vida de projetos de ciência de dados, situada logo após a coleta. Sua relevância reside na necessidade de compreender profundamente a natureza das informações antes de explorar algoritmos, permitindo identificar valores discrepantes (outliers), dados faltantes ou atributos redundantes. Este artigo aborda como a aplicação de estatística descritiva e técnicas de visualização prepara o terreno para apresentações adequadas e modelos de machine learning de alta performance. Ao longo do texto, o leitor aprenderá conceitos fundamentais de variáveis, tendência central e dispersão, utilizando as principais bibliotecas da linguagem Python.
Introdução
No fluxo de um projeto de ciência de dados, logo após a definição do problema, a coleta e a análise exploratória dos dados assumem um papel protagonista. Longe de ser uma tarefa burocrática, a EDA é o alicerce que permite ao profissional compreender profundamente a natureza dos dados antes de propor soluções algorítmicas. Sem esse aprofundamento inicial, corre-se o risco de processar informações inválidas ou ignorar atributos redundantes, o que compromete a performance de modelos de machine learning e a clareza dos resultados apresentados aos clientes.
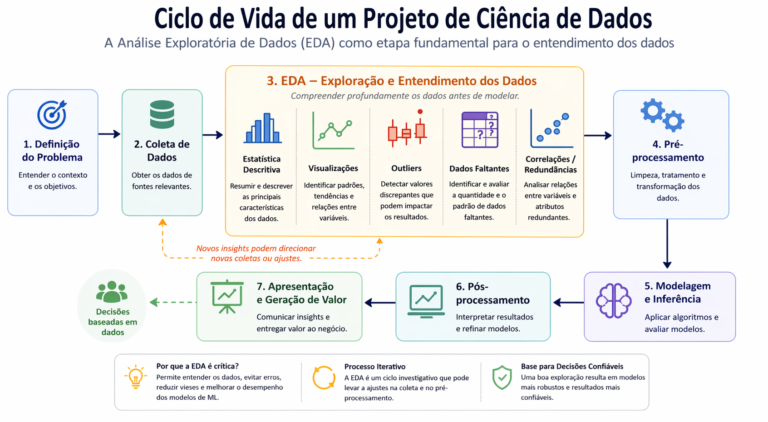
Figura 1: O Ciclo de Vida de um Projeto de Ciência de Dados coloca a Análise Exploratória (EDA) como o elo vital entre a coleta bruta e a modelagem. Como demonstra a ilustração, a EDA não é uma etapa linear, mas um processo iterativo e investigativo que permite diagnosticar outliers, tratar dados faltantes e validar hipóteses de negócio precocemente. Ao estabelecer essa base sólida de entendimento, o profissional reduz drasticamente o risco de propagar vieses para os algoritmos de Machine Learning, garantindo que as decisões finais sejam fundamentadas em padrões reais e não em ruídos estatísticos.
Estatística Descritiva e Conceitos Básicos
A estatística fornece o conjunto de técnicas para organizar, descrever e interpretar dados. Dentro deste campo, a Estatística Descritiva foca na organização e descrição via tabelas e gráficos, buscando facilitar a compreensão da natureza das informações. Para dominar esta etapa, é preciso compreender seus pilares fundamentais:
- População e Amostra: Enquanto a população abrange todos os indivíduos de um grupo, a amostra é o recorte utilizado em estudos onde analisar o todo é inviável ou inadequado.
- Dados Brutos vs. Rol: Os dados brutos representam a coleta inicial; o rol é a organização estratégica desses valores em ordem crescente ou decrescente.
- Classificação de Variáveis: As variáveis definem a natureza dos dados e podem ser:
- Qualitativas (Atributos): Divididas em nominais (sem hierarquia, como sexo) ou ordinais (com ordem implícita, como classe social).
- Quantitativas (Numéricas): Podem ser discretas (valores contáveis, como número de filhos) ou contínuas (mensuráveis em intervalos reais, como peso e altura).
- Tabelas de Frequência: São ferramentas essenciais para organizar a contagem (frequência absoluta) e a proporção (frequência relativa) das observações, permitindo visualizar a distribuição dos dados de forma simples ou acumulada.
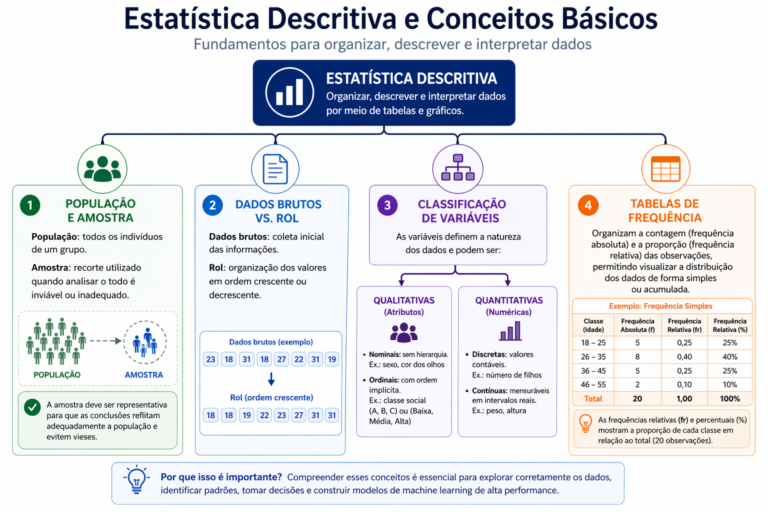
Figura 2: A Estatística Descritiva serve como a gramática básica da análise de dados, permitindo que o caos dos dados brutos seja organizado em estruturas interpretáveis. Como ilustrado, a transição para o “Rol” e a correta classificação das variáveis — sejam elas categóricas (qualitativas) ou numéricas (quantitativas) — determinam quais testes estatísticos e visualizações serão aplicáveis adiante. A correta estruturação em tabelas de frequência não apenas resume o volume de informações, mas revela a distribuição e a proporção de cada classe, fornecendo o contexto necessário para identificar onde a maior parte dos dados se concentra.
Funcionamento da Análise Exploratória
A análise exploratória utiliza esses fundamentos para resumir conjuntos de dados e extrair insights através de três frentes principais:
- Medidas de Posição: Média, mediana e moda indicam onde os dados se concentram.
- Medidas de Dispersão: Amplitude, variância, desvio padrão e coeficiente de variação medem o quão espalhados os dados estão em torno do centro.
- Medidas de Assimetria: Analisam o quanto a distribuição se afasta da simetria (curva normal), indicando se há maior concentração de valores à direita ou à esquerda do gráfico.
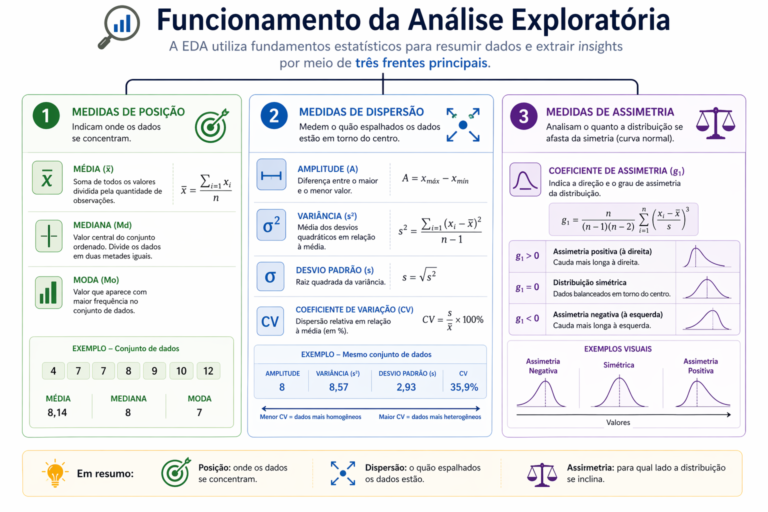
Figura 3: O funcionamento da Análise Exploratória de Dados (EDA) baseia-se no equilíbrio entre três frentes fundamentais: onde os dados se concentram (posição), o quão espalhados eles estão (dispersão) e qual a forma da sua distribuição (assimetria). Como ilustra o infográfico, métricas de dispersão absoluta e relativa, como o Desvio Padrão e o Coeficiente de Variação (CV), são indispensáveis para validar a homogeneidade do conjunto. Complementarmente, o Coeficiente de Assimetria revela a direção da “cauda” da distribuição, um indicador crítico para entender se a massa de dados está concentrada em valores baixos ou altos, permitindo antecipar comportamentos que algoritmos puramente matemáticos poderiam ignorar.
Medidas de Posição (Tendência Central)
Essas medidas indicam o grau de concentração dos dados e onde eles se localizam no conjunto. Os principais métodos incluem:
- Média: Existem vários tipos, como a aritmética, geométrica (comum em índices econômicos), harmônica e ponderada. É importante notar que a média é uma medida volátil, sendo altamente sensível a valores extremos (outliers).
- Mediana: Representa o valor que divide o conjunto em duas partes iguais. Diferente da média, é considerada uma medida robusta, pois não é afetada por outliers.
- Moda: Define o valor com a maior frequência de ocorrência no conjunto, servindo como outro indicador robusto de centralidade.
- Medidas Separatrizes (Quartis e Percentis): Dividem o conjunto em partes iguais — os quartis em 4 partes (25%, 50%, 75%) e os percentis em 100 partes. Elas são essenciais para entender a distribuição percentual e a posição relativa de um dado no todo.

Figura 4: As Medidas de Posição ou de Tendência Central são ferramentas essenciais para resumir um conjunto de dados em um único valor representativo. Como destacado no comparativo, a escolha da métrica ideal depende diretamente da natureza dos dados: enquanto a média é altamente volátil e sensível a valores extremos, a mediana e a moda mostram-se medidas robustas para descrever o comportamento central em distribuições assimétricas. Além disso, a introdução das Medidas Separatrizes (Quartis e Percentis) permite uma análise mais granular da posição relativa de cada dado, sendo a base fundamental para a construção de ferramentas visuais poderosas, como o Boxplot.
Dica: Em conjuntos de dados com muitos outliers, a mediana costuma ser uma métrica mais confiável que a média para representar a realidade dos dados.
Medidas de Dispersão e Assimetria
Para compreender o quão espalhados os dados estão em torno da média e como se comporta a forma da distribuição, utilizamos os seguintes indicadores:
- Amplitude: É a medida mais simples de dispersão, definida pela diferença entre o maior e o menor valor do conjunto. Embora limitada, oferece uma visão rápida do alcance dos dados.
- Variância e Desvio Padrão: Medem a dispersão absoluta. Enquanto a variância utiliza o quadrado das distâncias, o desvio padrão é mais intuitivo para análise, pois retorna à mesma unidade de medida dos dados originais.
- Coeficiente de Variação: Uma medida adimensional que expressa o desvio padrão como um percentual da média. É a ferramenta ideal para medir a homogeneidade do conjunto; valores abaixo de 25% costumam indicar dados homogêneos.
- Assimetria: Assimetria (Skewness): Geralmente medida pelo Coeficiente de Pearson, indica o grau de deformação da curva de frequências. Ela revela se os dados estão concentrados à esquerda (assimetria positiva) ou à direita (assimetria negativa) em relação à curva normal de uma distribuição simétrica.
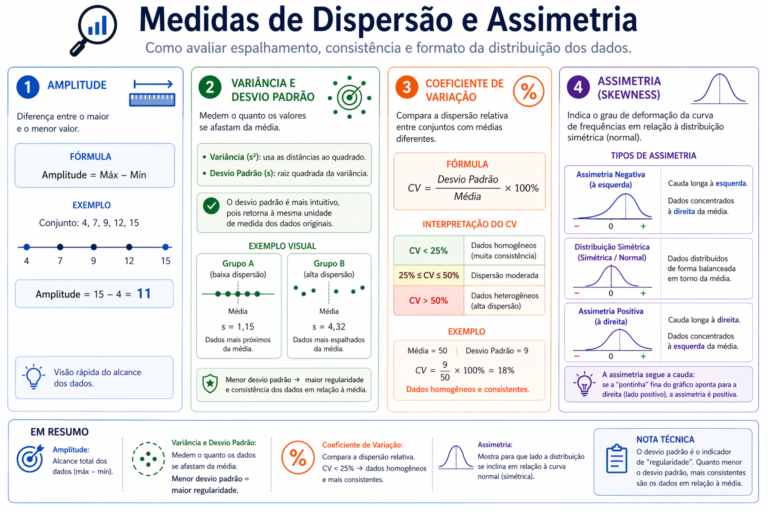
Figura 5: Enquanto as medidas de tendência central indicam o “equilíbrio” dos dados, as Medidas de Dispersão e Assimetria revelam sua estabilidade e comportamento nas extremidades. Como demonstrado, o Coeficiente de Variação (CV) é uma ferramenta poderosa para comparar a variabilidade entre conjuntos de escalas diferentes, onde valores abaixo de 25% geralmente apontam para dados homogêneos. Já a análise de Assimetria (Skewness) é vital para identificar a direção da cauda da distribuição: uma assimetria positiva indica que, apesar da concentração em valores menores, existem valores extremos à direita que podem puxar a média para cima, um insight crítico para qualquer estratégia de pré-processamento.
Nota Técnica: O desvio padrão é o indicador de “regularidade”. Em contextos de comparação, quanto menor o desvio padrão, mais consistentes são os dados em relação à média.
Visualização de Dados e Relacionamento entre Variáveis
A escolha da técnica visual adequada é determinada pelo tipo de variável e pelo objetivo da análise. As abordagens são divididas entre descrição de categorias, distribuição e correlação:
Visualização por Tipo de Variável
- Variáveis Qualitativas: Para representar atributos e categorias, utilizam-se gráficos de pizza (para poucas categorias) e gráficos de barras ou colunas (ideais para comparações diretas).
- Variáveis Quantitativas:
- Histogramas: Essenciais para visualizar a distribuição de dados contínuos.
- Gráficos de Linhas: Utilizados para identificar tendências em séries temporais.
- Gráficos de Dispersão (Scatter Plot): Ferramenta principal para visualizar a relação e o padrão de associação entre duas variáveis numéricas.
Técnicas Comparativas e de Diagnóstico
- Diagrama de Caixas (Boxplot): É uma das ferramentas mais poderosas da EDA. Permite visualizar, em um único gráfico, a distribuição dos dados, os quartis (medidas separatrizes) e a presença de outliers (valores discrepantes).
- Análise de Correlação: Utiliza-se de matrizes e mapas de calor (heatmaps) para quantificar o nível de associação entre os preditores e a variável-alvo. O coeficiente varia de -1 a +1:
- +1: Correlação positiva perfeita (ambas crescem juntas).
- 0: Ausência de relação linear.
- -1: Correlação negativa perfeita (uma cresce enquanto a outra diminui).
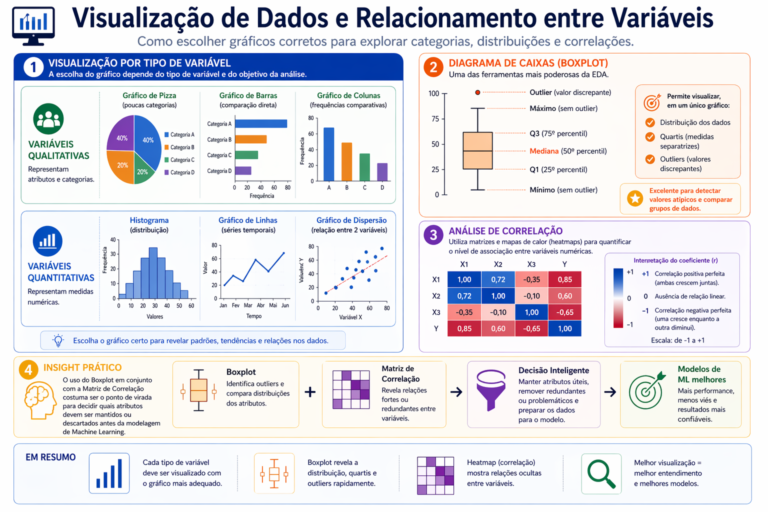
Figura 6: A visualização de dados na EDA atua como uma ponte entre os cálculos estatísticos e a interpretação humana, permitindo identificar padrões e anomalias de forma imediata. Como ilustrado, a escolha do gráfico correto — seja um Histograma para entender a distribuição ou um Gráfico de Dispersão para visualizar correlações — é o primeiro passo para uma análise precisa. Destacam-se o Boxplot, pela sua capacidade ímpar de revelar quartis e valores discrepantes (outliers) em um único quadro, e a Matriz de Correlação, que quantifica o nível de associação entre variáveis. Integrar essas ferramentas não apenas facilita o entendimento dos dados, mas é o ponto de virada para decisões estratégicas, como a seleção de atributos (feature selection) para modelos de Machine Learning mais robustos.
Insight: O uso do Boxplot em conjunto com a Matriz de Correlação costuma ser o ponto de virada para decidir quais atributos devem ser mantidos ou descartados antes da modelagem de Machine Learning.
Exemplos Práticos e Ferramentas
Para aplicar os conceitos de análise exploratória, o profissional de Ciência de Dados utiliza um ecossistema de bibliotecas especializadas e datasets clássicos que ilustram desafios reais.
Ferramentas Python
A aplicação prática desses conceitos é facilitada por ecossistemas de bibliotecas especializadas:
- Pandas: Essencial para manipulação de dados tabulares (Dataframes).
- NumPy: Base para computação científica e arrays multidimensionais.
- Matplotlib: Biblioteca de baixo nível que permite alta customização de gráficos.
- Seaborn: Interface de alto nível baseada em Matplotlib para gráficos estatísticos atraentes com menos código.
Aplicações no Mundo Real
O uso dessas técnicas vai além do código, aplicando-se a cenários críticos:
- Medicina: O estudo de uma amostra de sangue para diagnóstico de anemia ilustra perfeitamente a impossibilidade de utilizar a população total do paciente.
- Economia: A aplicação de médias geométrica e harmônica é indispensável para calcular a inflação e deflacionar séries históricas (como IGP e IPCA).
Estudo de Caso: Dataset Iris
O dataset Iris (criado em 1936) é frequentemente utilizado para demonstrar EDA. Com ele, é possível carregar dados de sépalas e pétalas de três espécies de flores e executar análises como:
- Sumário Estatístico: Através do comando iris.describe(), obtém-se instantaneamente média, desvio padrão e quartis de todos os atributos.
- Visualização Multidimensional: O uso de Scatter Plots revela a relação entre comprimento e largura das pétalas, enquanto o Boxplot identifica visualmente a dispersão e a presença de potenciais outliers.
- Análise de Associação: A Matriz de Correlação quantifica como os atributos das flores se relacionam entre si, orientando a seleção de variáveis para modelos futuros.
O domínio dessas bibliotecas permite que o cientista de dados saia da teoria estatística e construa diagnósticos visuais rápidos e precisos.
Boas Práticas e Cuidados na EDA
Para garantir que a análise exploratória seja precisa e não induza a erros de interpretação, é fundamental seguir diretrizes de rigor estatístico e visual.
Recomendações e Boas Práticas
- Priorize Medidas Robustas: Em conjuntos de dados com alta variabilidade ou presença de outliers, prefira a mediana em vez da média aritmética para representar o centro dos dados.
- Análise de Homogeneidade: Utilize o Coeficiente de Variação para comparar a dispersão entre grupos com médias muito diferentes; lembre-se que valores abaixo de 25% são um bom indicador de constância.
- Interpretação Direta: Prefira sempre o desvio padrão em vez da variância para relatórios, pois ele mantém a mesma escala dos dados originais.
- Visualização Adequada: Escolha o gráfico correto para o tipo de variável. Use pizza ou barras para qualitativas; histogramas e scatter plots para quantitativas.
- Diagnóstico Visual: Utilize o Boxplot como ferramenta padrão para identificar valores discrepantes e comparar distribuições entre diferentes categorias de forma rápida.
- Eficiência com Seaborn: Aproveite a sintaxe de alto nível do Seaborn. O comando pairplot, por exemplo, gera uma matriz completa de correlações e distribuições com apenas uma linha de código.
Limitações e Erros Comuns
- Sensibilidade ao Outlier: A média aritmética e o coeficiente de correlação são altamente voláteis. Ignorar o impacto de valores atípicos nessas métricas pode distorcer completamente a percepção da realidade.
- Dados não Ordenados: Tentar calcular a mediana sem colocar os dados em rol (ordem crescente ou decrescente) é um erro básico frequente.
- Escala da Variância: Lembre-se que a variância está em uma escala quadrática, o que dificulta sua interpretação direta em comparação ao desvio padrão.
- Escolha Inadequada de Gráficos: Variáveis qualitativas e quantitativas exigem representações diferentes. Usar o gráfico errado pode ocultar padrões importantes ou gerar conclusões errôneas.
- Equilíbrio de Ferramentas: Embora o Seaborn seja visualmente superior, ele possui limitações de customização. O ideal é combinar o poder estético do Seaborn com a flexibilidade do Matplotlib para ajustes finos.
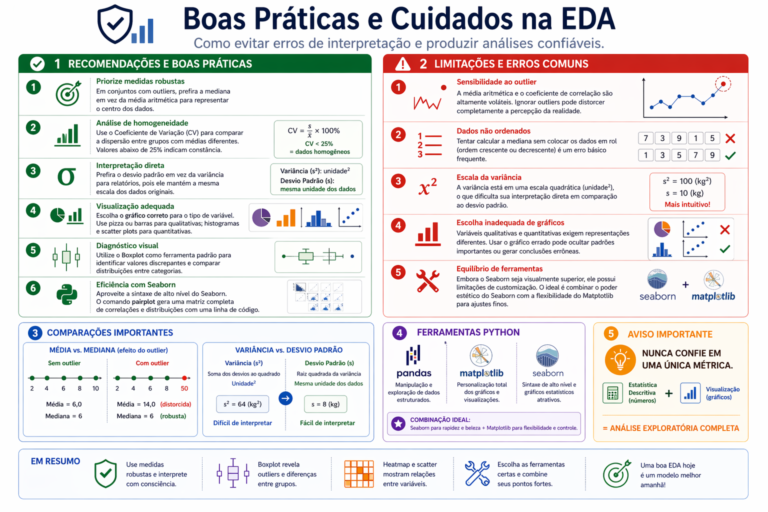
Figura 7: O sucesso de uma Análise Exploratória de Dados (EDA) reside menos na complexidade das ferramentas e mais no rigor metodológico aplicado. Como detalhado no guia de boas práticas, erros simples — como negligenciar a ordenação dos dados para o cálculo da mediana ou ignorar a escala quadrática da variância — podem comprometer toda a interpretação de um projeto. A maturidade técnica do analista revela-se na combinação estratégica do ecossistema Python, unindo a manipulação de dados do Pandas à estética do Seaborn e ao controle granular do Matplotlib. Em última análise, a regra de ouro é nunca confiar em uma única métrica isolada: a verdadeira inteligência de dados emerge da interseção entre o rigor dos números da estatística descritiva e a clareza visual dos gráficos.
Aviso: Nunca confie em uma única métrica. A combinação de estatística descritiva (números) com visualização (gráficos) é a única forma de garantir uma análise exploratória completa.
Conclusão
A análise exploratória e a visualização de dados não são apenas preliminares, mas o alicerce fundamental para o sucesso de qualquer iniciativa de Ciência de Dados. Ao transformar dados brutos em conhecimento acionável, o profissional ganha a capacidade de identificar problemas precocemente e compreender padrões ocultos que algoritmos sozinhos poderiam ignorar.
Dominar as medidas de tendência central, a variabilidade e as ferramentas do ecossistema Python (como Pandas e Seaborn) permite que o desenvolvedor garanta uma base sólida e confiável para a modelagem. Em última análise, uma EDA bem executada é o que diferencia um experimento instável de um modelo de Machine Learning robusto, preciso e verdadeiramente alinhado aos objetivos do negócio.
Referências
- KALINOWSKI, M.; ESCOVEDO, T.; VILLAMIZAR, H.; LOPES, H. Engenharia de Software para Ciência de Dados: um guia de boas práticas com ênfase na construção de sistemas de machine learning. 1. ed. São Paulo: Casa do Código, 2023.
Compartilhe:
Gostou do conteúdo? Se este guia te ajudou a entender como a Análise Exploratória de Dados transforma números brutos em conhecimento estratégico — das fórmulas estatísticas ao ecossistema Seaborn — compartilhe este artigo! Ajude mais pessoas a dominarem a etapa fundamental que diferencia um experimento instável de um modelo de Machine Learning robusto e confiável.